配置中心¶
数据诊断¶
在推荐业务中,数据质量的好坏决定了后续的数据清洗及业务效果。数据智能诊断提供对user,item,行为表的数据的探查,发现其中隐藏的数据质量问题。为提高数据完整性以及特征质量提供辅助分析以及后续改进建议。
目前数据诊断支持 5 种诊断任务,分别为:
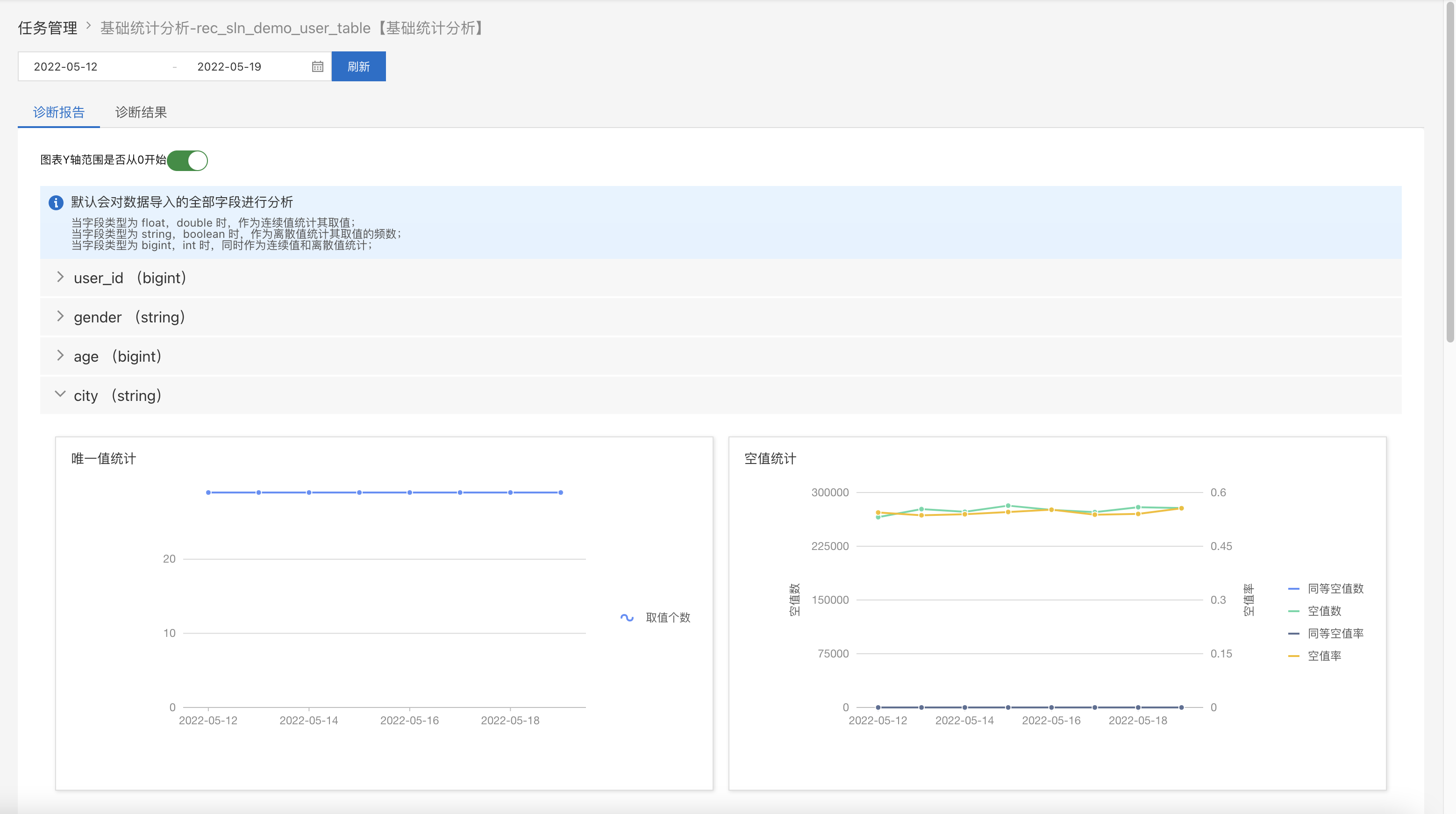
基础统计分析:分析特征的各方面基础统计信息,如数据总量、取值数、空值数、特征取值的百分位数、特征取值频数的百分位数(包括最大值、最小值、中位数)、取值和取值频数的等距分桶数据的分布直方图等
物品/用户 变化率分析:分析每天的用户或物品的增加/减少量和增加/减少率
用户留存率分析:分析用户的周期(T+k天内)留存率和单天(第T+k)留存率(仅适用于行为表)
两表关联分析:分析两表关联时,关联字段各自没有关联上的数量所占比例,并分析在各个维度上的关联异常
异常行为分析:分析有上下游依赖的行为中,行为异常的情况,如有点击没有曝光等(仅适用于行为表)
下面以基础统计分析为例讲解诊断步骤:
新建任务

任务类型:选择基础统计分析
数据表:待诊断的数据表
任务名称:自定义名称
分区字段:数据表的分区字段
Tag字段:多值类的特征字段
KV字段:KV 类特征字段
Text字段:文本类特征字段
其他字段:没有特殊要求,使用默认值即可
周期运行:是否每天定时运行诊断任务
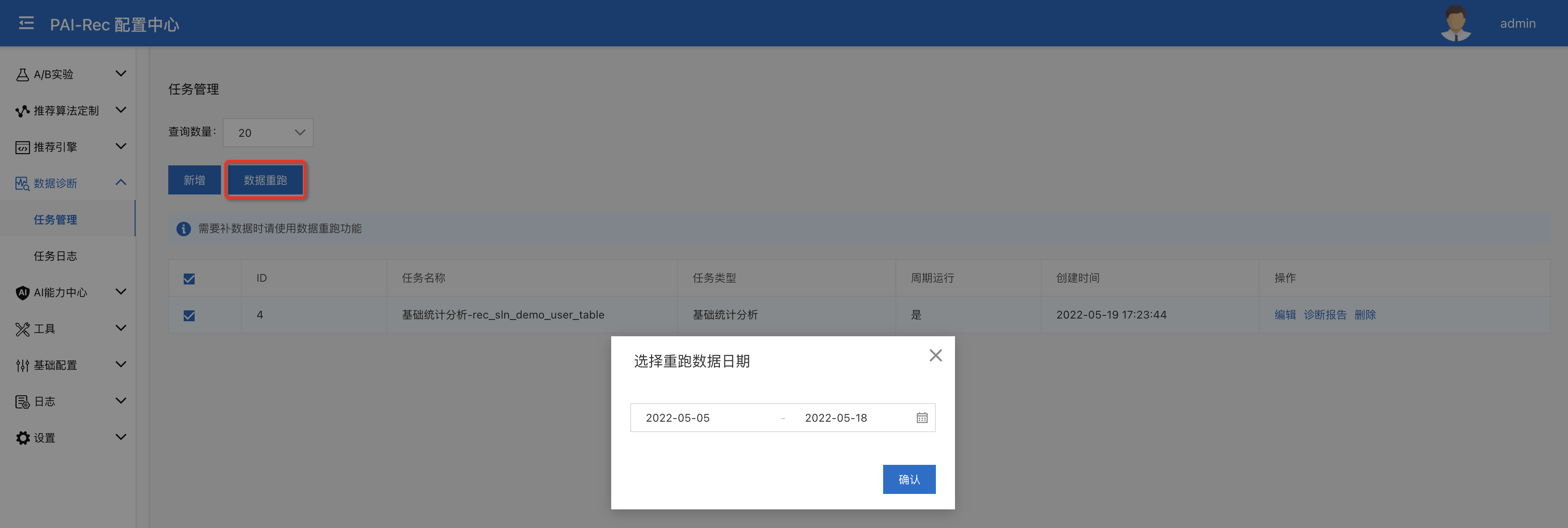
执行任务
创建完成之后,勾选已有的任务,点击【数据重跑】,选择补数据周期,点击确认即可
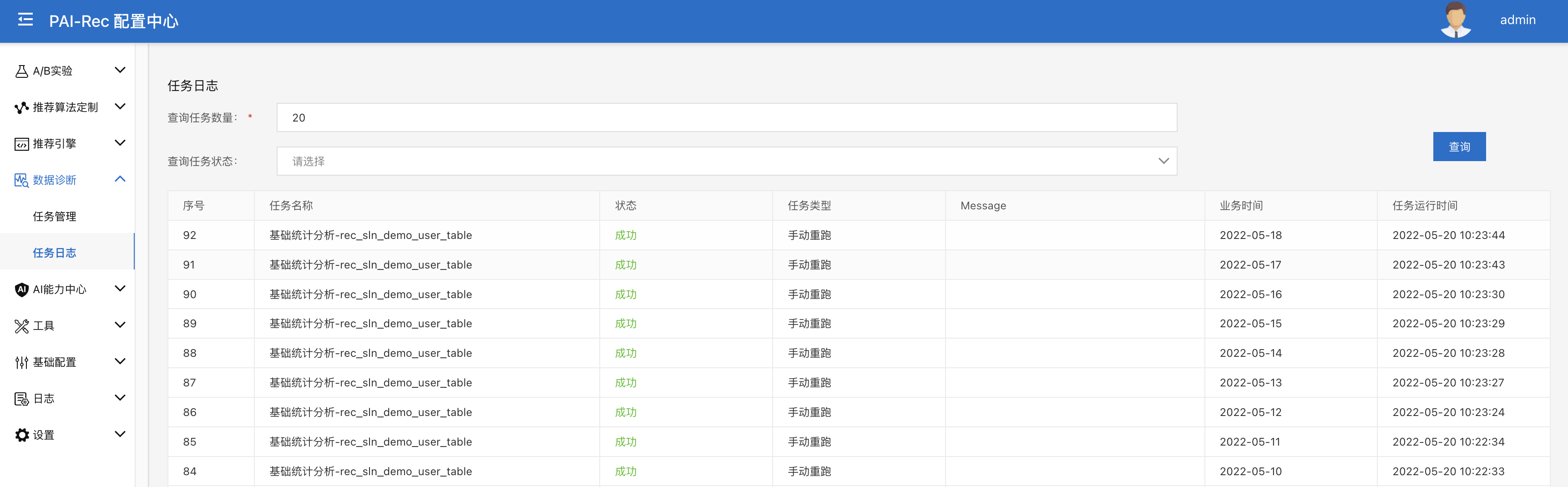
查看日志
在【任务日志】页面可以看到数据诊断任务的运行日志
诊断报告
在【数据诊断/任务管理】页面,点击相应任务的诊断报告,可以查看具体任务的诊断报告
推荐引擎¶
推荐引擎配置¶
在 pairec 推荐引擎(go 版)中, 最重要的就是 config.json 配置文件。
本模块的功能就是将配置文件的管理放到配置中心,配置文件可以在配置中心可视化管理,可以进行格式校验,以及更新的版本跟踪。
与 pairec 推荐引擎集成后,引擎可以感知到配置的变化,热更新推荐策略。某些参数需要容器重启才能有效,如 AlgoConfs、HologresConfs 等元信息配置。
服务列表¶
引擎开发好之后,我们想要部署到 EAS 上,或者后期引擎版本的迭代,一种方法是在 ECS 上通过 eas 脚本进行发布更新,也可以通过此页面进行版本迭代。
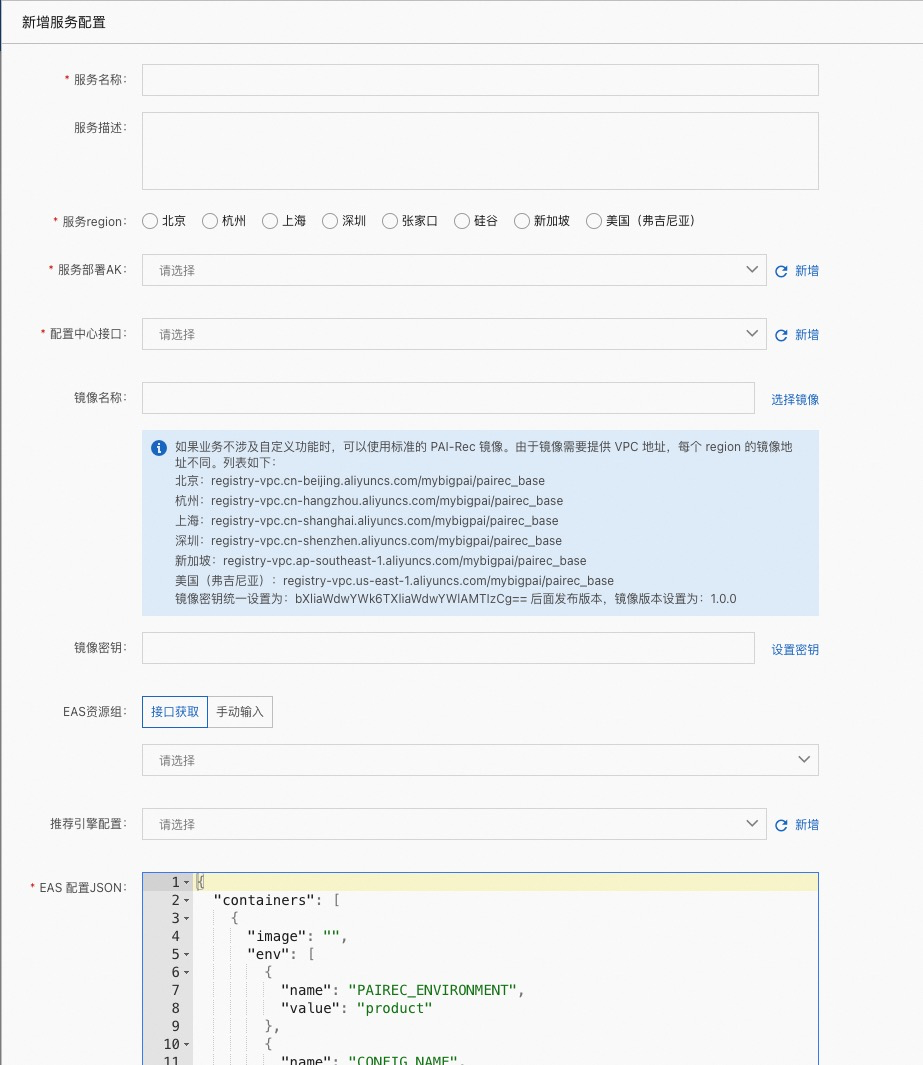
服务名称:自定义名称
服务描述:对此服务的详细描述
服务 region:要发布到哪个 region 的 EAS
服务部署AK:账号的 AK 信息
配置中心接口:配置中心 server 的服务接口,配置中心初始化时会自动创建。
镜像名称:可以选择 PAI 团队提供的基础镜像,镜像名称为上图蓝色框内。也可以选择自定义镜像,点击右侧【选择镜像】会列出此 AK 下【容器镜像服务/个人版】中的镜像仓库名称
镜像密钥:docker registry的认证信息,目前支持username:password | base64的方式,点击【设置密钥】,填入用户名密码,可以自动生成 base64 编码。
EAS资源组:私有资源组名称。如果接口获取不到,可以手动输入。
推荐引擎配置:推荐引擎配置中的配置名称
EAS 配置 JSON:上面参数选择好会自动同步到此 JSON 中。也可以直接手动更改。
发布单管理¶
发布单管理主要是进行发布版本的控制。
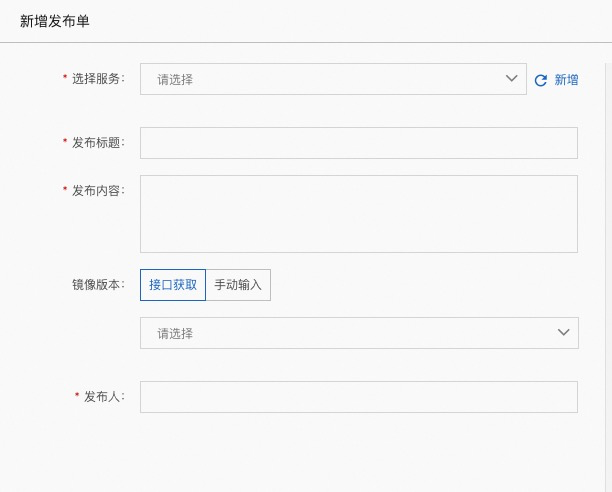
选择服务:服务列表中创建的服务
发布标题:发布的标题
发布内容:此次发布详细的说明
镜像版本:接口获取不到,可以手动输入
发布人:责任人
发布之后,会发布一个预发服务,测试之后没问题,点击【测试通过】,此时可以进行生产环境的发布。
参数管理¶
待定。
特征平台¶
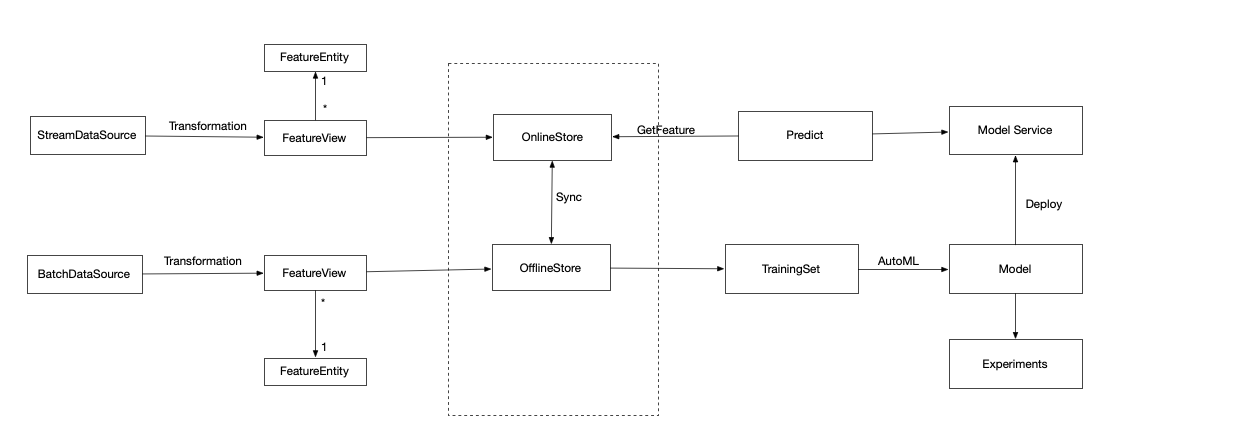
FeatureStore从字面意义上可以理解为“特征的存储”,但是在实际应用中,除了存储之外,其还在模型训练、模型服务、特征发现等功能。
解决了什么问题?
通常,离线和在线的数据及特征对齐工作往往会耗用大量的时间。一方面是因为离在线数据生成规则需要做到一一对应,这点在没有数据工具的服务助情况下,往往是效率低下的。并且无法利便利的应用团队和他人已有的数据成果,存在离线在线特征共享和管理困难。
由于算法是一个迭代过程,需要在特征、样本、模型调优之间多次,每次的调整在整个流程之间需要小心的保证规则的完整,这点存在很大效率负担。另外,在模型成功上线后,如果模型发生问题了,往往也是因为数据发生错误,而造成的模型服务产生问题,这里涉及到模型数据的监控以及模型数据的诊断,怎样支持这样的需求显得非常重要。所在这里可以抽象出来需要解决的主要问题:
离线在线特征统一
特征快速衍生迭代
特征资产共享和权限
特征质量和版本控制
架构概览
项目管理(Project)¶
我们可以通过 project 可以创建多个项目空间,每个项目空间是独立的。project 里会配置基本的信息,每个 project 会对应一个 offlinestore 和 onlinestore
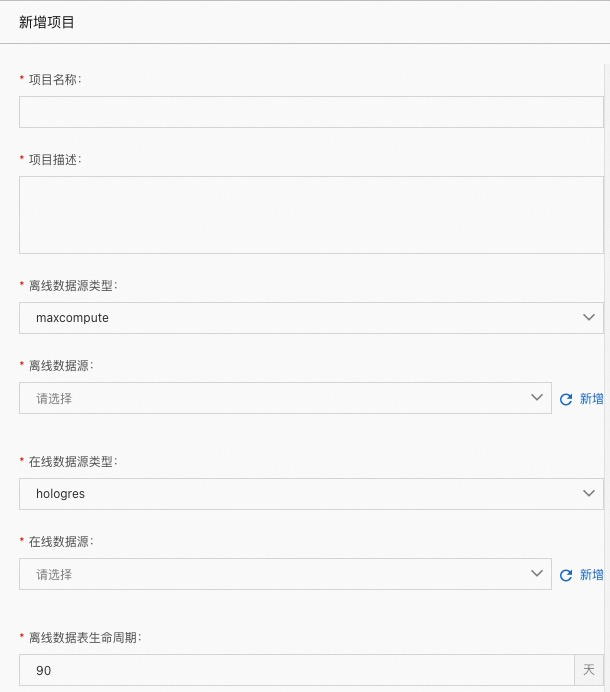
项目名称:自定义名称
项目描述:关于 project 的详细描述
离线数据源类型:目前支持 maxcompute 和 spark
离线数据源:在数据源管理中定义好的数据源
在线数据源类型:目前支持 hologres、igraph、mysql、redis
在线数据源:在数据源管理中定义好的数据源
离线数据表生命周期:表的生命周期( lifecycle )
特征实体(FeatureEntity)¶
FeatureEntity 描述了一组相关的特征集合。多个 FeatureView 可以关联一个 FeatureEntity。 每个Entity 都会有一个 Entity JoinId , 通过 JoinId 可以关联多个 FeatureView 特征。每一个 FeatureView 都有一个主键(索引键)来获取其下面的特征数据,但是这里的索引键可以和 JoinId 定义的名称不一样
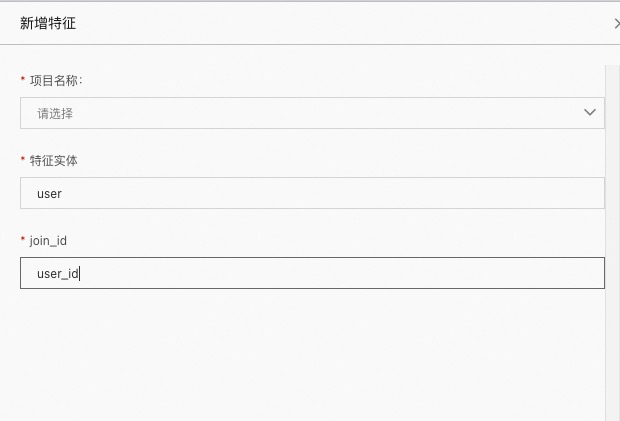
项目名称:该特征实体所属的项目名称
特征实体:特征实体的名称,如上图中填写的 user
join_id:多个 FeatureView 进行关联的主键,如上图中 user_id
特征检索(FeatureView)¶
FeatureView 指定了数据从哪里来(DataSource), 数据进入FeatureStore 需要哪些转换(特征工程/Transformation), 特征 schema (特征名称+类型),数据需要放到哪里(OnlineStore/OfflineStore)、特征meta(主键、事件时间、分区键, FeatureEntity, ttl )。
FeatureView 会分为两种类型, BatchFeatureView 和 StreamFeatureView 。 BatchFeatureView 可以把离线数据注入到 FeatureStore 中, StreamFeatureView 支持实时特征的写入。 BatchFeatureView 会把数据管理到 OfflineStore 里, 然后可以选择同步到 OnlineStore 里。StreamFeatureView 会把数据写入到 OnlineStore 里,然后同步到 OfflineStore 里, 但实际上我们会把同样的数据同时写入到里面。
FeatureView 包含多个记录,每条记录主键进行标识,每条记录还有个可选的事件时间(event_time) 字段,标识特征是何时产生的。 event_time 是可选的。 当有 event_time 时, 特征写入到 OnlineStore 时, 会判断当 event_time >= online 里的记录时, 才会更新数据。 如果没有event_time , 主键相同就会覆盖。
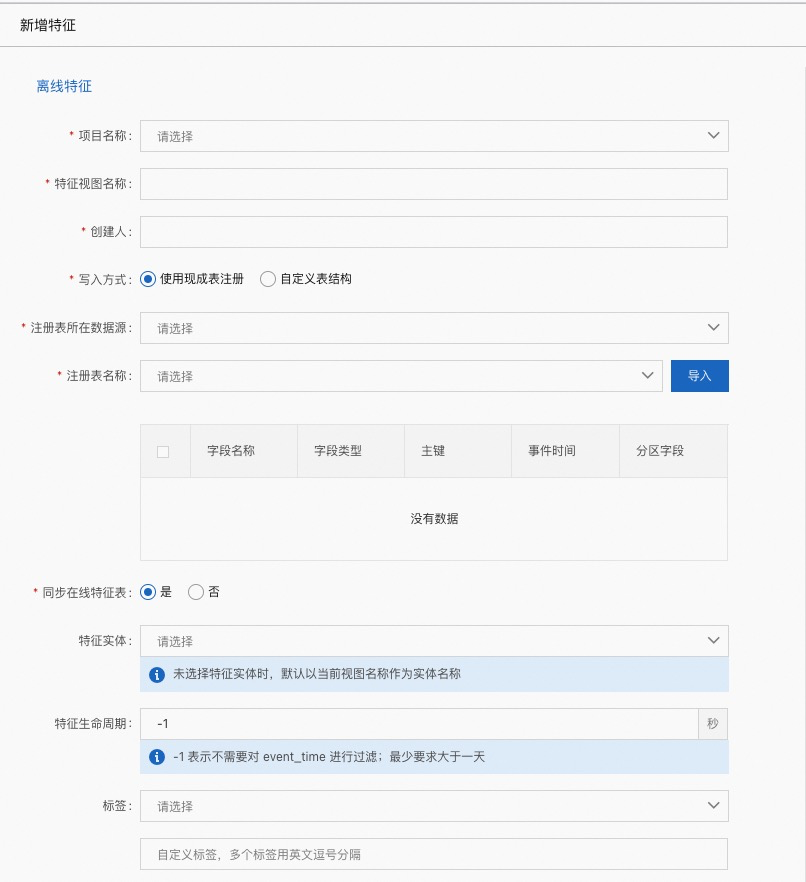
项目名称:此 FeatureView 所属项目(Project)
特征视图名称:自定义特征视图名称(FeatureView)
创建人:创建人
写入方式:
使用现成表注册:
注册表所在数据源:注册表所在数据源
注册表名称:此数据源下的表名
自定义表结构:自定义字段名称,字段类型等信息
同步在线特征表:是否同步到 hologres
特征实体:属于哪个特征实体(FeatureEntity)
特征生命周期:表的生命周期
标签:描述待定
Label 表管理¶
label 表的字段主要由以下几部分组成, request_id(可选), entity join_id(user_id, item_id 等),特征(onDemand feature), label 字段, event_time 时间戳字段。我们单独把label表拿出来注册,方便后面使用。
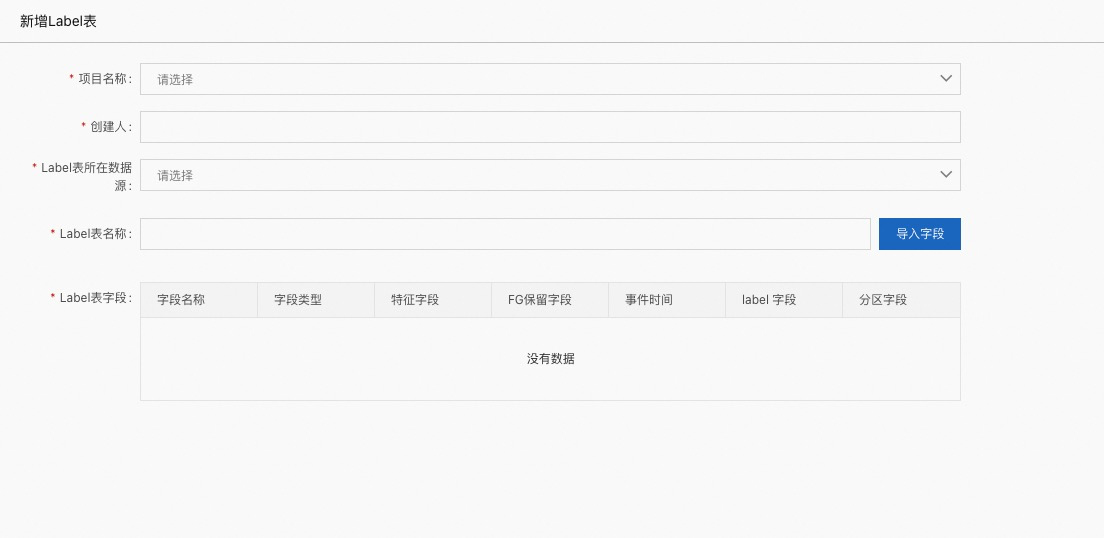
项目名称:Label 所属项目(Project)
创建人:创建人名称
Label 表所在数据源:Label 表所在的数据源,如 mysql 中的 test 库,需提前配置
Label 表名称:table 名
Label 表字段:选择表中所需要的字段
模型管理¶
从 offlinestore 的角度讲,我们最终是训练出模型,变成服务进行业务的预测。 那么训练的样本可以从上面的 TrainingSet 获得, 然后就是模型训练,最终会部署成服务。
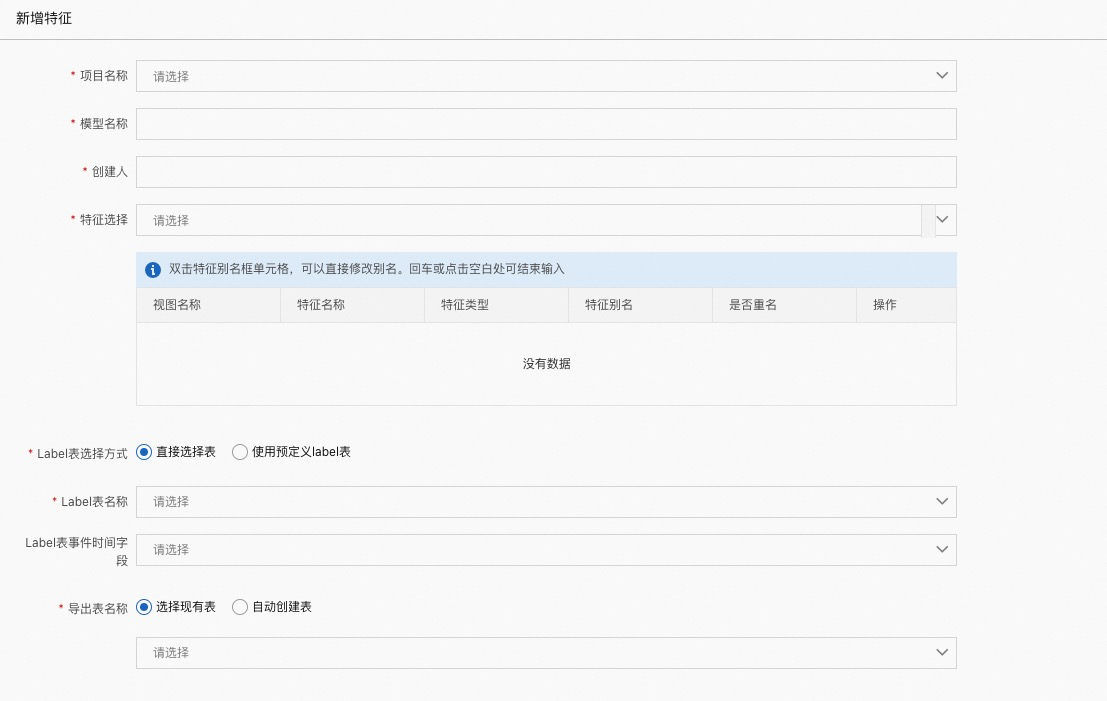
项目名称:模型所属项目(Project)
模型名称:自定义名称
创建人:创建人
特征选择:列出所选项目(Project)下的所有特征视图(FeatureView),和特征视图下的特征,选择所需特征
Label 表选择方式:
直接选择表:会列出所属项目(Project)下的所有表
Label 表名称:选择所需表名
Label 表事件时间字段:表的时间事件字段
使用预定义 Label 表:使用通过【Label 表管理注册的 label 表】
Label 表名称:选择注册号的 Label 表
导出表名称:选择导出表的生成方式
选择现有表:选择已经存在的表,并将数据写入
自动创建表:重新 Create Table,并预览建表语句
任务中心¶
任务导出时的日志信息
工具¶
一致性检查¶
本功能用于自动化进行离在线特征一致性对比工作,排查以下问题:
特征不匹配,体现在在线的特征名称与离线的特征不匹配
特征类型不匹配, 相同的特征名称,在线离线类型不匹配
特征缺失, 在线的特征缺失,或者没有构造出相应的特征。传入的上下文特征没有,或者在线服务没有构造出相关特征
特征值不匹配,在线的特征值的处理逻辑或者方法与离线的构造不一致
模型的特征处理逻辑有误, processor 在打分之前,如果需要对特征的处理,比如 easyrec, 这块特征处理涉及特征加载,特征默认值,特征的生成等等。这里通过开启 processor debug 模式,获取生成的特征,来做进一步的对比
流程图如下:
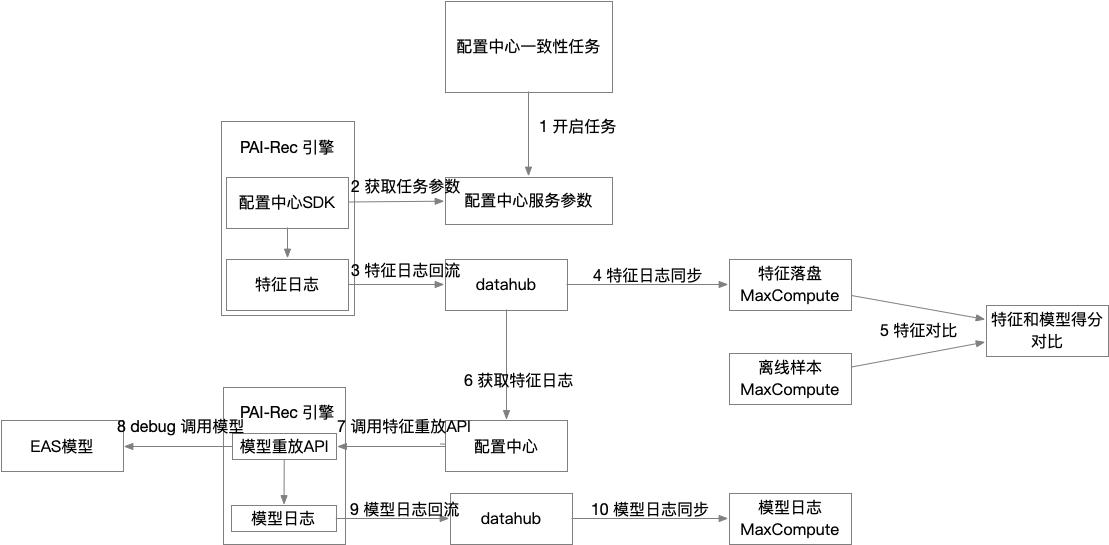
新增一个一致性任务
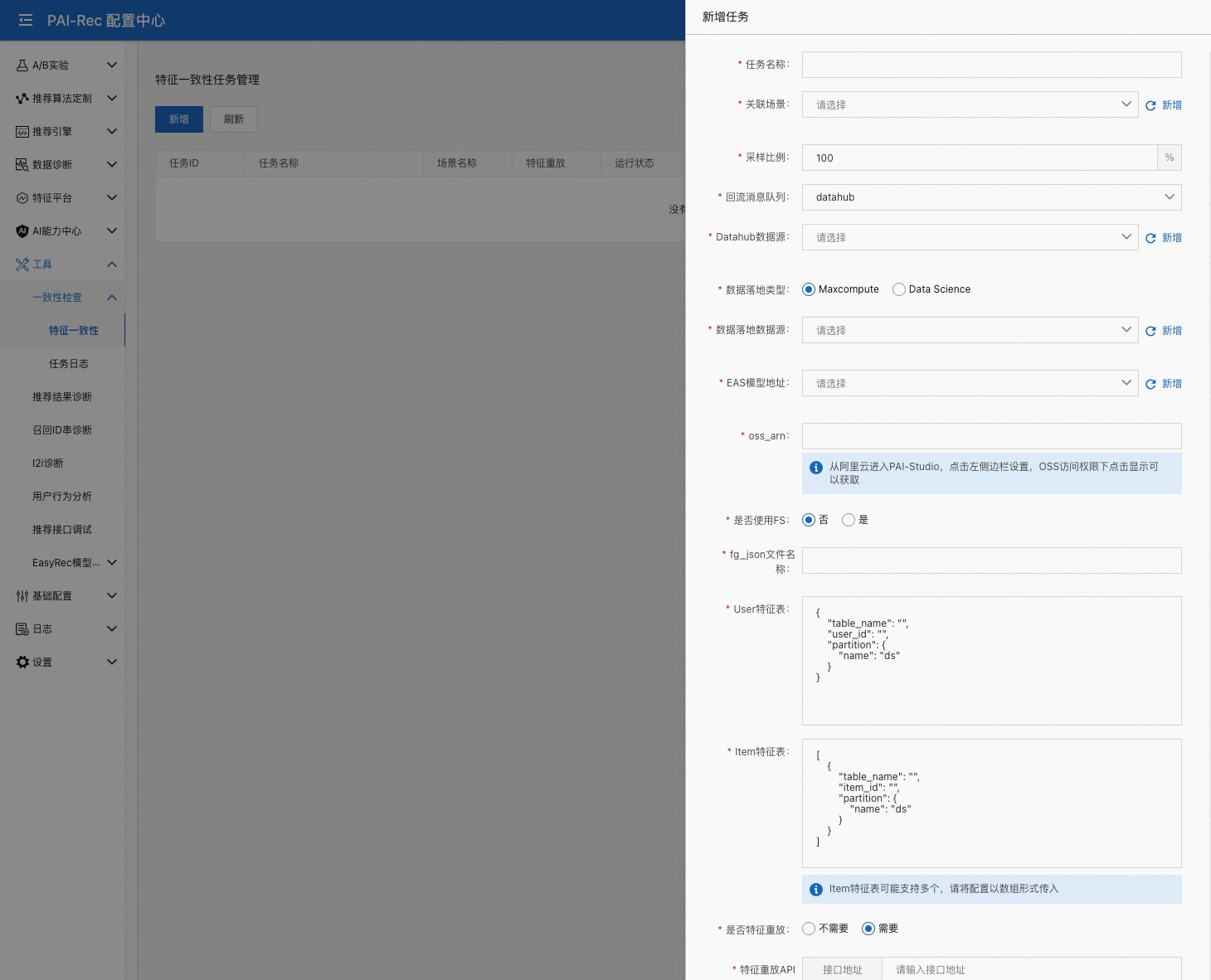
任务名称:自定义任务名称
关联场景:任务与哪个推荐场景进行关联
采样比例:N% 的数据会进行特征重放,特征重放会把模型中详细的特征信息保存下来
回流消息队列:目前仅支持 datahub
Datahub数据源:选择要使用的 datahub,需要在【数据源管理】中提前配置
落地数据类型:会将日志信息解析为表,此处是指将表落在哪里,目前支持 maxcompute 和 data science
EAS 模型地址:推荐引擎当前正在使用的模型,一般配置为 VPC 地址,需要在【数据源管理】中提前配置
oss_arn:访问 oss 的权限信息
是否使用FS:是不是选择使用 feature store(特征平台)?
不使用需要手动配置两个特征表,使用的话只需要选择特征平台上已经配置好的信息即可
否:
fg_json 文件名称:maxcompute 中训练模型所使用的 fg.json 文件
User 特征表:此处需要配置 User 特征表的表名、主键、分区字段
Item 特征表:此处需要配置 Item 特征表的表名、主键、分区字段
是:
fg_json文件名称:非必填项,可以指定 maxcompute 中训练模型所使用的 fg.json 文件,不指定的情况下,会使用 fs model 的 json 文件
Experiment_Server地址:配置中心 server 的地址,配置中心创建时,会自动在【数据源管理】注册
Project名称:特征平台模块,要使用的 Project
Model:要使用的 model
UserId:user entity 的 join_id
ItemId:item entity 的 join_id
是否特征重放: 重放特征就是打开 easyrec 的 debug 模式,可以获取到模型中特征的详细信息
需要
接口地址:此处需要填写引擎服务的地址+/api/feature_reply
EAS token: 引擎服务的 token
重放消息队列:目前仅支持 datahub
Datahub数据源:特征重放日志信息要使用的 datahub
高级设置:
aliyun_id:此账号的 aliyun_id
workflow_name:Dataworks 中的业务流程名称
oss bucket:oss 的路径,会将一致性工具生成的脚本上传到此路径下
配置好之后可以点【启动任务】,这里要选择和引擎对应的环境,然后点击【确认】即可
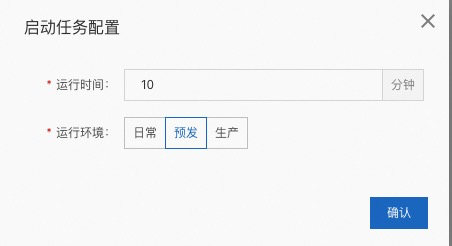
如果此时引擎没有流量,需要手动打一些请求给引擎
推荐结果诊断¶
推荐接口完成后,算法同学希望可以可视化的看到推荐结果,推荐结果诊断, 用于模拟调用推荐接口,对返回的数据进行扩充,比如针对 itemid 可以增加更多想展示的内容,比如图片、视频、标题、描述等等,方便直观的感知推荐结果是否可靠。
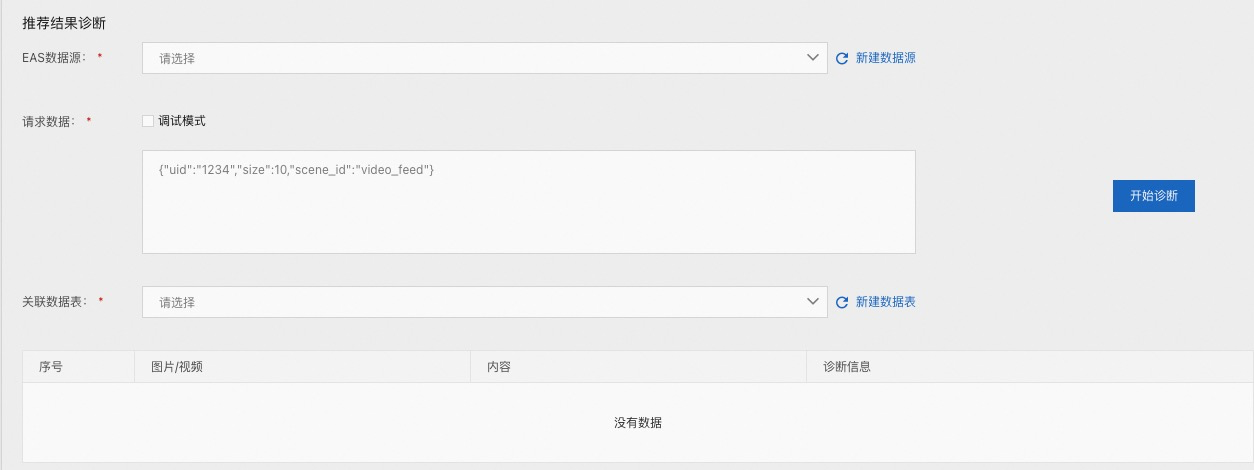
EAS 数据源:引擎的请求地址,需提前在【数据源管理】中进行配置
请求数据:http 请求的 body,选择【调试模式】,会自动在 body 中加入
"debug":true参数关联数据表:item 的元数据信息表。需要提前在【数据表管理/实验工具表】中配置
召回 ID 串诊断¶
这里主要是分析召回的 ID 列表是不是可靠的。这里逻辑相对简单,根据召回 id 获取到 item 的基本信息。在展现形式上,与推荐结果诊断也是一致的。
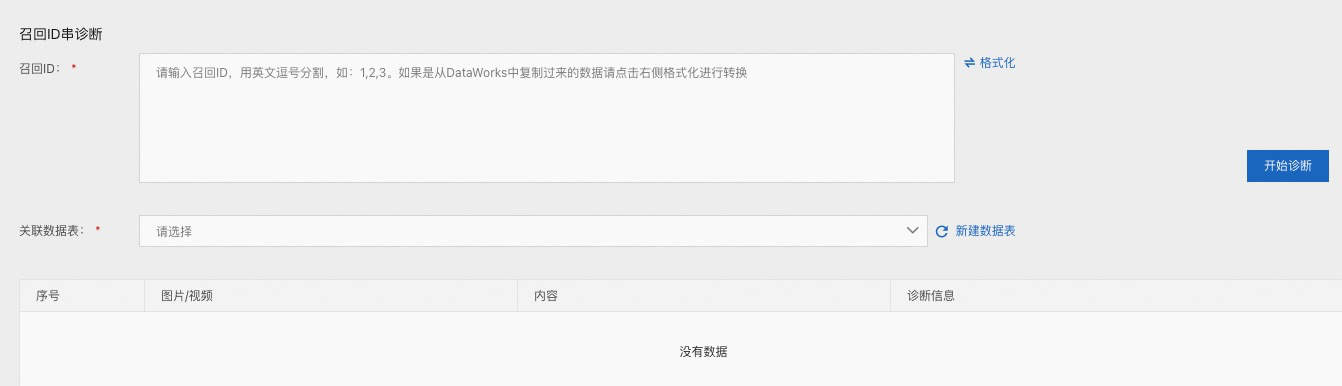
召回 ID:召回 ID 串,逗号分隔
关联数据表:item 的元数据信息表。需要提前在【数据表管理/实验工具表】中配置
I2i 诊断¶
【I2i 诊断】其实是【召回 ID 串诊断】的扩展,不再需要手动输入召回 ID,而可以根据 u2i2i 召回和 i2i 召回将召回 ID查询出来,填充到下面方框中,其中 u2i 表和 i2i 表的格式我们是约定好的
u2i 表
字段 |
类型 |
说明 |
|---|---|---|
user_id |
string |
用户id, 保持唯一性 |
item_ids |
string |
用户浏览的 item id 列表。 支持格式: Itemid1,itemid2,itemid3 |
i2i 表
字段 |
类型 |
说明 |
|---|---|---|
item_id |
string |
item id , 保持唯一性 |
similar_item_ids |
string |
i2i 相似 item id 列表。 支持格式: Itemid1:score1,itemid2:score2,itemid3:score3 |
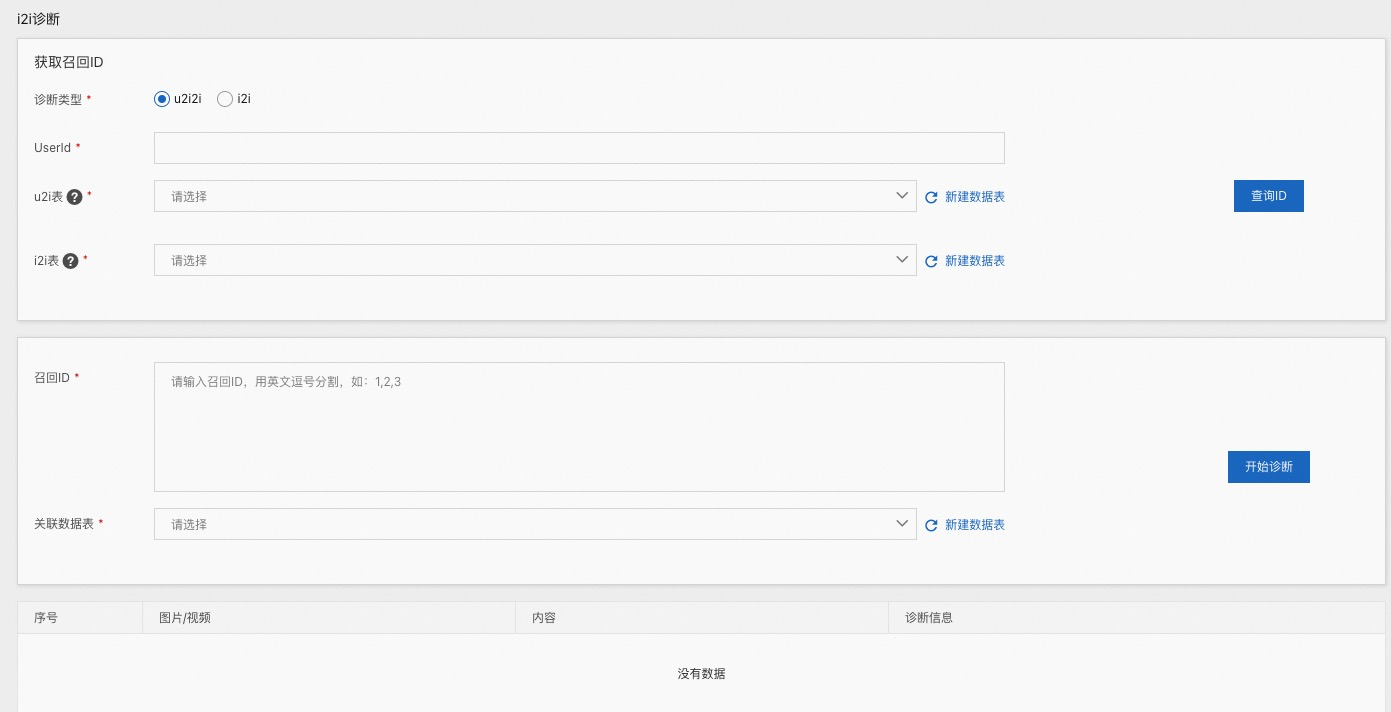
UserId:用户 id
u2i 表:u2i 表,格式如上
i2i 表:i2i 表,格式如上
召回 ID:当配置好上面几个参数之后,点击【查询 ID】,会自动填充此参数
关联数据表:item 的元数据信息表。需要提前在【数据表管理/实验工具表】中配置
用户行为分析¶
用户行为分析 , 用于查看某个用户的历史行为,比如曝光,点击,收藏,分享等等,可以看到历史行为相关的 item 信息。
这里需要用到用户的行为表。在这里,行为表我们也是约定好的,主要字段包括如下。这里列出的是主要字段,下面的表可以扩充更多的字段。
CREATE TABLE user_behavior (
"uid" text NOT NULL,
"itemid" text NOT NULL,
"event" text NOT NULL,
"timestamp" timestamptz NOT NULL
......
)
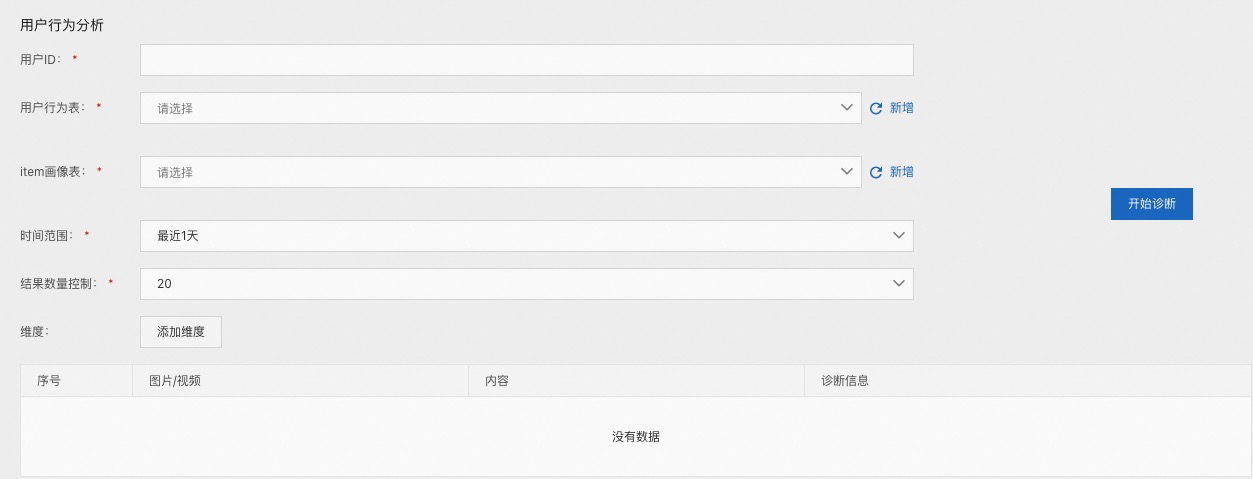
用户 ID:
用户行为表:用户行为表,需提前在【数据表管理】中创建
item 画像表:item 的画像表,需提前在【数据表管理】中创建
时间范围:用户行为表中的时间范围
结果数量控制:展示的数量,相当于 order by timestamp limit N
推荐接口调试¶
对服务发起一个 http 请求,并展示结果
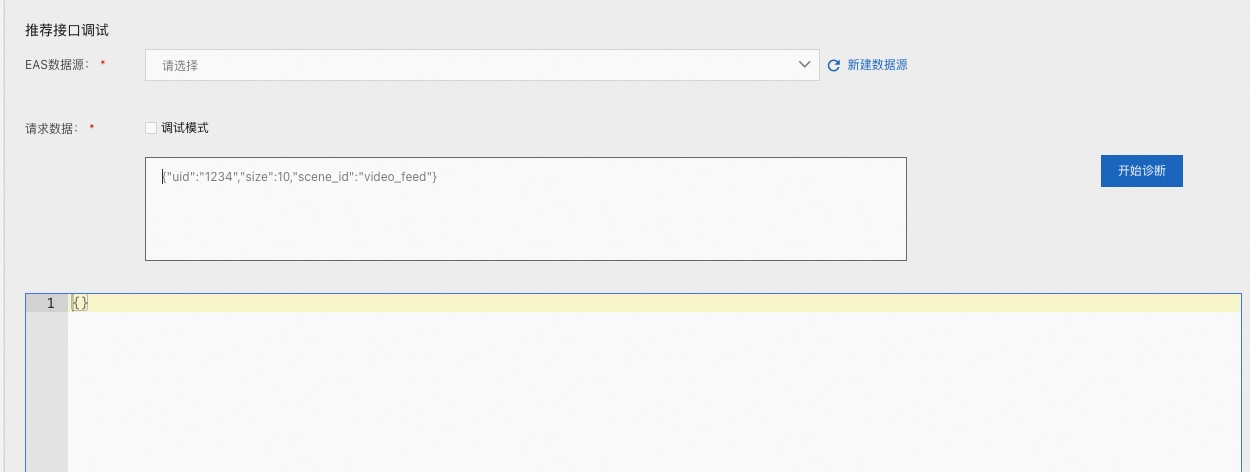
EAS 数据源:引擎的请求地址,需提前在【数据源管理】中进行配置
请求数据:http 请求的 body
EasyRec 模型管理¶
基础配置¶
我们在使用其他模块时,如A/B实验,数据诊断等都需要填写很多相同的信息,故在此将其抽象出来,统一配置,配置好之后在其他模块直接选择即可。
AK管理¶
此处是对 ak 信息的管理,填入对应 AccessKeyId 和 AcessKeySecret 即可。

点击【删除】时,如果此 AK 在其他地方已经被使用,则无法删除成功,必须先解除引用。
数据源管理¶
数据源管理目前支持 8 种类型:hologres,maxcompute,datahub,eas,oss,mysql,spark,kubernetes。
hologres
当数据源类型为 hologres 时

数据源名称:自定义名称
网络地址:可从 hologres 控制台网络信息处获取
数据库名称:db 的名称
关联AK:访问此数据库需要用到的 AK 信息,需提前在 AK 管理中配置
maxcompute
当数据源类型为 maxcompute 时

数据源名称:自定义名称
所在Region:实例所在的 region,如果是专有云,可以点击自定义,此时可以填入专有云的 endpoint
项目名称:maxcompute 的项目名称
关联AK:访问此项目需要用到的AK信息
datahub
当数据源类型为 datahub 时

数据源名称:自定义名称
所在Region:实例所在的 region,如果是专有云,可以点击自定义,此时可以填入专有云的 endpoint
项目名称:datahub 的项目名称
关联AK:访问此项目需要用到的AK信息
eas
当数据源类型为 eas 时

数据源名称:自定义名称
服务接口地址:eas 服务的地址
例如: 若想访问 eas 上推荐引擎的推荐接口
eas控制台的地址为: http://xx.cn-beijing.pai-eas.aliyuncs.com/api/predict/test_rec
引擎中的路由地址为: api/rec/home_feed
则此处的服务接口地址应填:http://xx.cn-beijing.pai-eas.aliyuncs.com/api/predict/test_rec/api/rec/home_feed
Token:访问此 eas 服务的 Token
oss
当数据源类型为 oss 时

数据源名称:自定义名称
所在Region:实例所在的 region,如果是专有云,可以点击自定义,此时可以填入专有云的 endpoint
OSS地址:oss 的路径
关联AK:访问此项目需要用到的AK信息
mysql
当数据源类型为 mysql 时
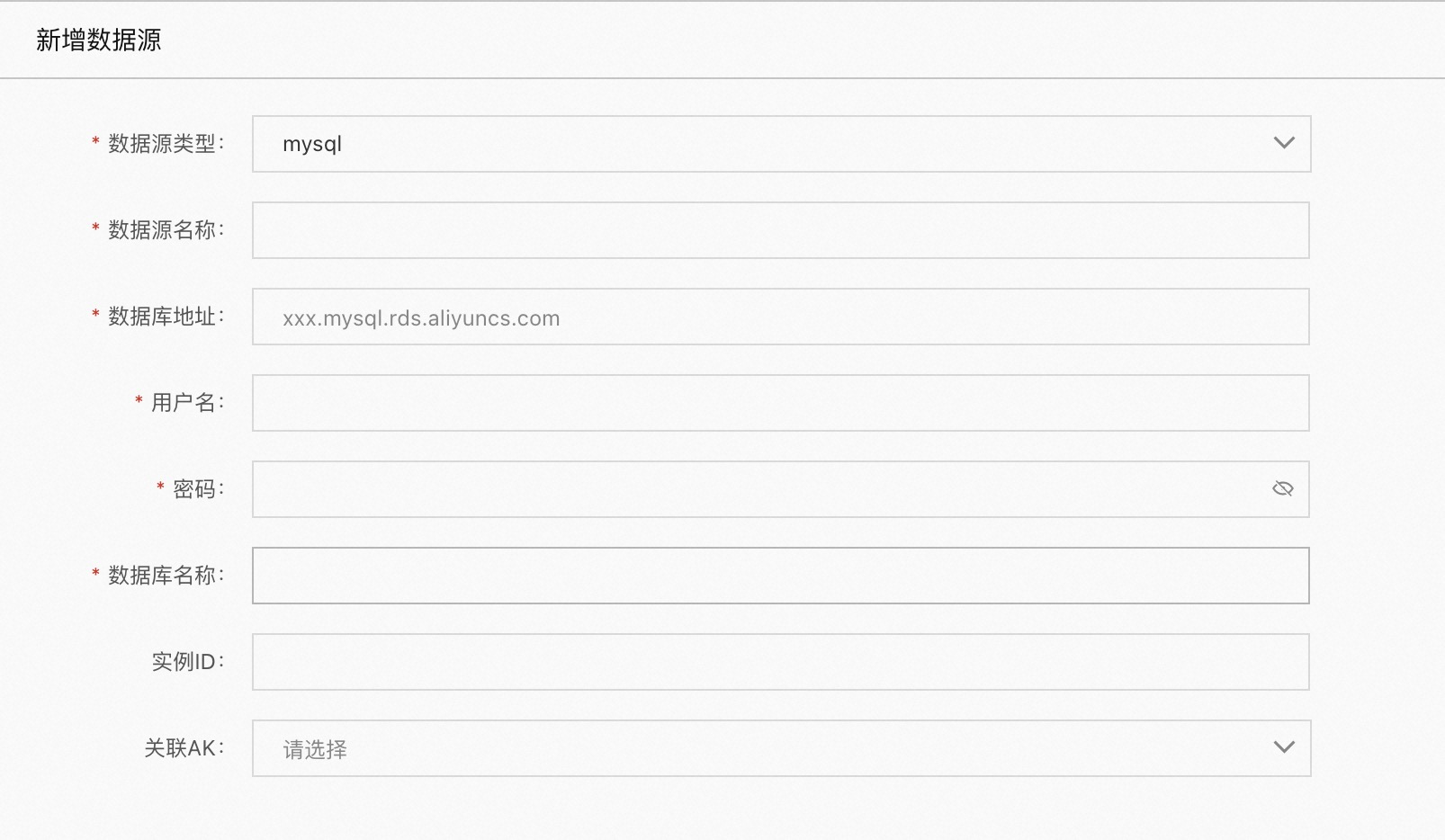
数据源名称:自定义名称
数据库地址:实例的访问地址
用户名:用户名
密码:密码
数据库名称:db 名称
实例ID:非必填项,可从 rds 控制台/实例详情中获取
关联AK:访问此项目需要用到的AK信息
spark
当数据源类型为 spark 时

数据源名称:自定义名称
数据库地址:实例的访问地址,一般为 ip:端口 类型
用户名:用户名
密码:密码
数据库名称:db 的名称
kubernetes
当数据源类型为 kubernetes 时
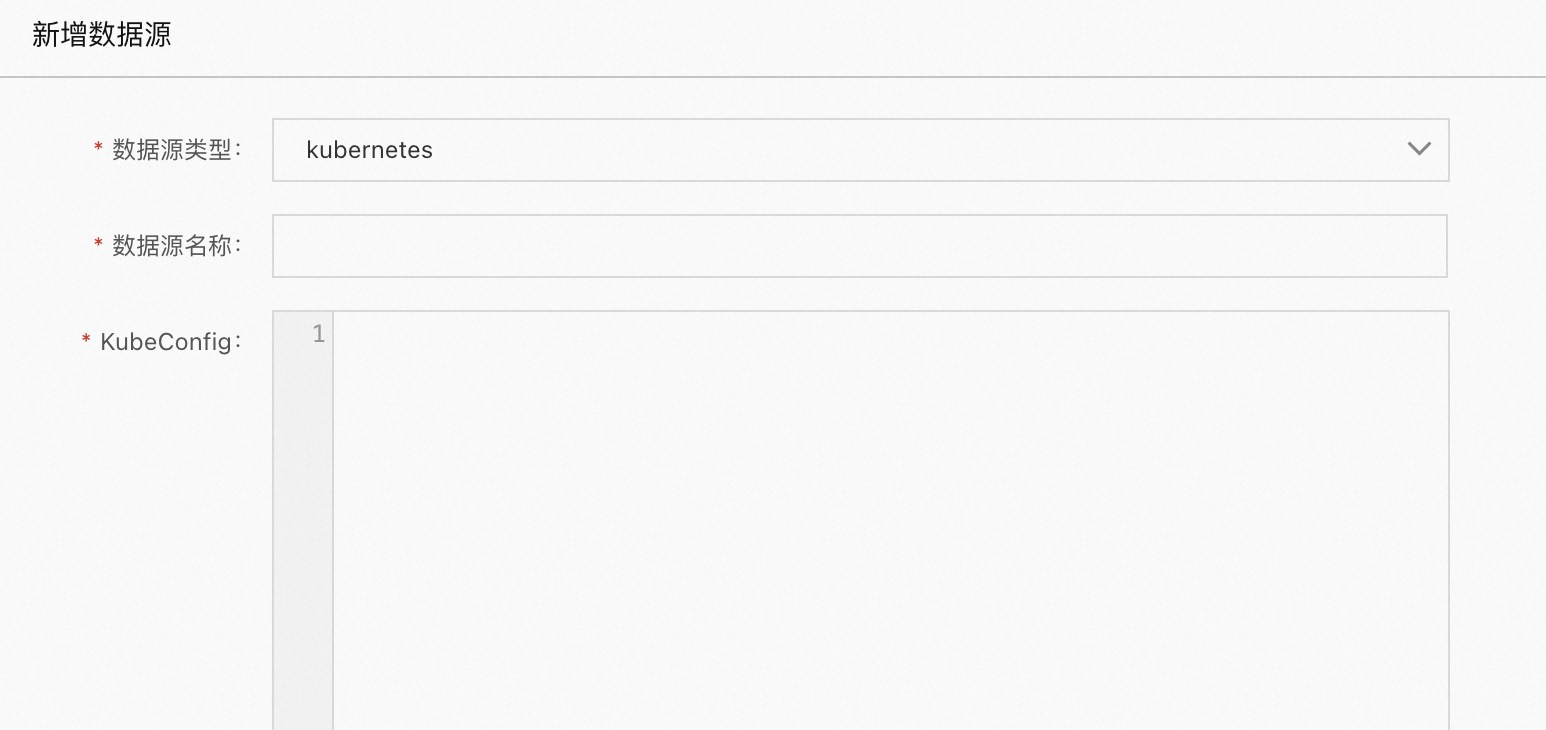
数据源名称:自定义名称
KubeConfig:kubernetes 集群的 Config
master ip:非必填项,master 的 ip
数据表管理¶
数据表管理分为推荐数据表、实验数据表、实验工具表,三种类型的配置是基本一样的,只是应用于不用模块,其中:
推荐数据表应用于【推荐诊断】模块
实验数据表应用于【A/B实验】模块
实验工具表应用于【工具】模块
新增的数据表目前支持 maxcompute、hologres、spark、mysql 四种类型,配置都是基本一样的,下面以 maxcompute 表举例:
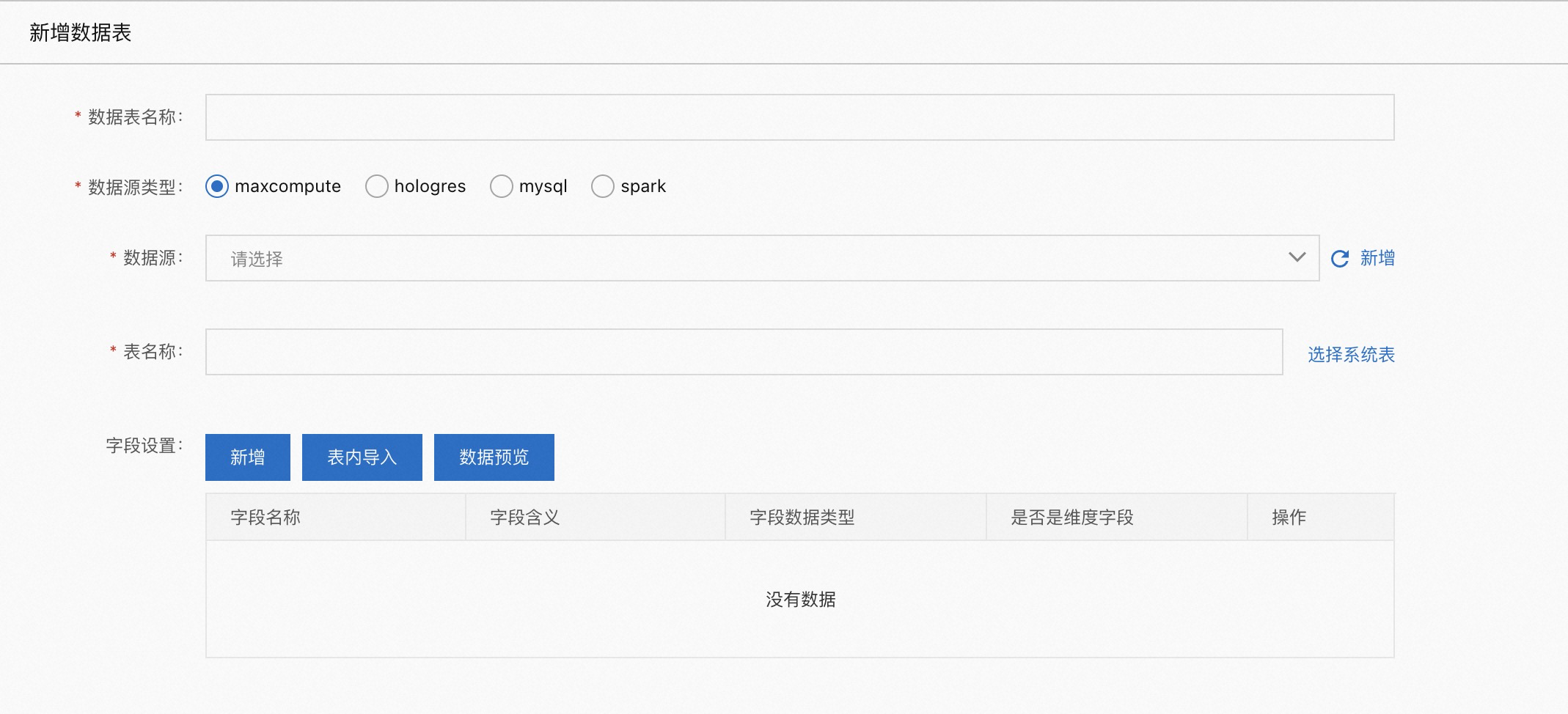
数据表名称:自定义名称
数据源:【数据源管理】中配置的数据源
表名称:数据库中 table 的名称
字段设置:
新增:可以新增一个字段,包含字段名、字段含义,字段类型,是否是维度字段。这里的【新增】只是停留在配置中心使用,并不会在数据库中为表新增字段。
表内导入:将表的字段导入进来
数据预览:只有 maxcompute 类型的数据表会有此选项,会跳转到 dataworks 的数据地图页面
场景管理¶
场景管理经常指代客户的业务场景,若要创建新的场景,如下
