特征平台支持新模型上线¶
修改特征后,需要重新上线训练的模型,以下以增加一个 user 特征表 和 一个 item 特征表为例介绍,如何在增加特征表后,上线新的推荐模型。
1. 新特征表在特征平台注册¶
新注册特征表可以分为网页操作和 python sdk 操作,可以选一种方式完成。
网页操作:特征平台网页操作
Python SDK 操作:特征平台 Python SDK 操作
2. 在特征平台中创建新模型¶
新特征表注册完成后,需要创建新模型,创建新模型分为网页操作和 python sdk 操作,可以选一种方式完成。
网页操作:特征平台网页操作
Python SDK 操作:特征平台 Python SDK 操作
3. 创建 eas 服务¶
eas 服务主要用于接收线上请求,推理模型,拿到打分后返回给推荐引擎。 在 dataworks 里面,选择业务流程,选择 通用,选择新建节点,如下图所示:
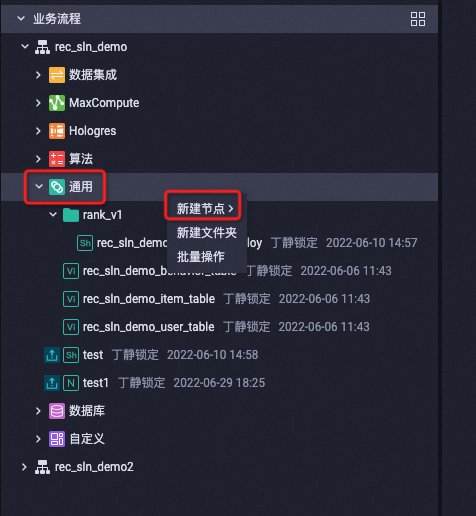
在新建节点里面选择 shell.
然后将以下内容复制到 shell 脚本中:
ymd=$1
cat << EOF > echo.json
{
"metadata": {
"cpu": 16,
"gateway": "default",
"gpu": 0,
"instance": 2,
"memory": 64000,
"name": "fs_model_v1",
"resource": "",
"rpc": {
"enable_jemalloc": 1,
"max_queue_size": 256
}
},
"model_config": {
"fg_mode": "tf",
"fs_host": "xxxx",
"fs_token": "xxxx",
"fs_model": "fs_model_name",
"fs_project": "project_name",
"fs_entity": "item",
"outputs": "probs",
"period": 2880,
"prefetch_feature_hot_ids": true,
"steady_mode": true
},
"model_path": "oss://your_bucket/easyrec/model_path/20230328/export/final_with_fg",
"processor_entry": "libtf_predictor.so",
"processor_path": "https://easyrec.oss-cn-beijing.aliyuncs.com/processor/LaRec-0.9.7b-77ad29d-TF-2.5.0-Linux.tar.gz",
"processor_type": "cpp",
"warm_up_data_path": ""
}
EOF
/home/admin/usertools/tools/eascmd -i id -k ak -e pai-eas.cn-beijing.aliyuncs.com create echo.json
# /home/admin/usertools/tools/eascmd -i id -k ak -e pai-eas.cn-beijing.aliyuncs.com modify dnn_online_deep_rank_v1 -s echo.json
其中第 4 行到第 16 行是指定 eas 配置相关的信息,具体可以参考 eas 配置文档: 第 17 行到第 28 行是指定 processor 相关的信息,其中需要填写的 feature store 相关的信息是 fs_host, fs_token, fs_model (模型名称), fs_project (项目名称),fs_entity (实体名称)。 第 29 行制定了用 EasyRec 训练好的模型导出的信息,第 31 行指定了 processor 的地址。第 37 行是调用 eascmd 创建 eas 服务, id 和 ak 要替换为实际的 id 和 ak, cn-beijing 也要根据实际区域进行修改。 注意 create 只能 create 一次,不能在重复 create, 如果需要更新服务,可以把 37 行注释掉,把 38 行取消注释,详细可以见下方的:设置 eas 服务更新例行。
4. 设置任务例行¶
要维持服务效果正常,需要设置例行,例行主要包含数据特征同步和模型更新。其中数据同步是指将模型推理过程中所有用到的资源都发布到线上,可以让在线请求取到,模型更新是指每天模型训练完成后,能够更新到线上的 eas 服务进行推理。
4.1 设置数据特征同步任务例行¶
在 dataworks 中的业务流程,选择 MaxCompute, 选择数据开发,选择新建节点,如下图所示:
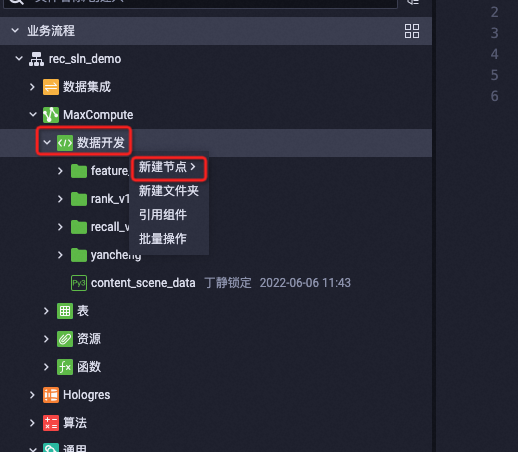
在新建节点中选择 pyodps 3. 然后将以下内容复制到 节点中:
from feature_store_py.fs_client import FeatureStoreClient
import datetime
def getdate(beforeOfDay):
today = datetime.datetime.now()
# 计算偏移量
offset = datetime.timedelta(days=-beforeOfDay)
# 获取想要的日期的时间
re_date = (today + offset).strftime('%Y%m%d')
return re_date
cur_day = getdate(1)
print("cur_day = ", cur_day)
host = 'http://12345/api/predict/pairec_experiment'
token = 'AAXXXXXBBBBB'
fs = FeatureStoreClient(host, token)
cur_project_name = 'fs_test'
project = fs.get_project(cur_project_name)
feature_view_name = 'fs_feature_view_1'
batch_feature_view = project.get_feature_view(feature_view_name)
if batch_feature_view is None:
ds = MaxComputeDataSource(data_source_id=offline_datasource_id, table=table_name)
feature_view = self.feature_store_project.create_batch_feature_view(
name='fs_feature_view_1',
owner='RecTemplate',
datasource=ds,
online=True,
entity='user',
primary_key='user_id',
register=True)
task = batch_feature_view.publish_table(partitions={'dt':cur_day}, mode='overwrite')
print(task.summary)
task.wait()
print(task.task_summary)
第 15 行指定了配置中心 server 端地址。第22行是先读取默认设置的特征视图,第一次运行如果没有的话会自动进行创建 (第 25 行),然后第 33 行进行特征同步,将数据由 offline store (max compute, spark) 同步到 online store (hologres, igraph, redis) 中。
4.2 设置 eas 服务更新例行¶
前面创建 eas 服务的代码如下:
ymd=$1
cat << EOF > echo.json
{
"metadata": {
"cpu": 16,
"gateway": "default",
"gpu": 0,
"instance": 2,
"memory": 64000,
"name": "fs_model_v1",
"resource": "",
"rpc": {
"enable_jemalloc": 1,
"max_queue_size": 256
}
},
"model_config": {
"fg_mode": "tf",
"fs_host": "xxxx",
"fs_token": "xxxx",
"fs_model": "fs_model_name",
"fs_project": "project_name",
"fs_entity": "item",
"outputs": "probs",
"period": 2880,
"prefetch_feature_hot_ids": true,
"steady_mode": true
},
"model_path": "oss://your_bucket/easyrec/model_path/20230328/export/final_with_fg",
"processor_entry": "libtf_predictor.so",
"processor_path": "https://easyrec.oss-cn-beijing.aliyuncs.com/processor/LaRec-0.9.7b-77ad29d-TF-2.5.0-Linux.tar.gz",
"processor_type": "cpp",
"warm_up_data_path": ""
}
EOF
#/home/admin/usertools/tools/eascmd -i id -k ak -e pai-eas.cn-beijing.aliyuncs.com create echo.json
/home/admin/usertools/tools/eascmd -i id -k ak -e pai-eas.cn-beijing.aliyuncs.com modify dnn_online_deep_rank_v1 -s echo.json
将第 37 行注释掉,将 38 行取消注释,这样就可以每天更新服务 (modify)。提交后即可例行。
5. 在 pairec 引擎配置添加服务¶
pairec 引擎配置可以参考 pairec 文档:引擎配置, 配置总览。
PAIREC 引擎侧配置主要是用来拉取 user 侧特征。一般配置时需指定特征平台地址,以及创建的 project 和 model 相关的信息。具体配置如下所示:
配置 server 端地址
"FeatureStoreConfs": {
"pairec-fs": {
"Host": "xxx",
"Token": "xxx",
"ProjectName": "demo_rank"
}
},
配置特征平台 model 名称和 entity 名称
"rank_v1": {
"AsynLoadFeature": true,
"FeatureLoadConfs": [
{
"FeatureDaoConf": {
"AdapterType": "featurestore",
"FeatureStoreName": "pairec-fs",
"FeatureKey": "user:uid",
"FeatureStoreModelName": "rank_v1",
"FeatureStoreEntityName": "user",
"FeatureStore": "user"
},
}
]
},
其中 FeatureStoreModelName 指定了特征平台中的模型名称,FeatureStoreEntityName 指定了 entity 名称。这里指定的 entity 名称是 “user”, 即会拉取所有挂在名为 “user” 的 entity 的特征表。不再需要指定具体的特征名。
6. 利用离线在线一致性工具测试整个在线推荐流程服务的一致性¶
部署完成后,可以利用离线在线一致性工具来对整个推荐流程服务测试一致性。离在线一致性的文档见:,以下是使用 特征平台 的示例。
6.1 config 配置¶
首先在工具的一致性检查页面选择特征一致性,然后点新增:

在是否使用 FS 时选择 是,如下图所示:
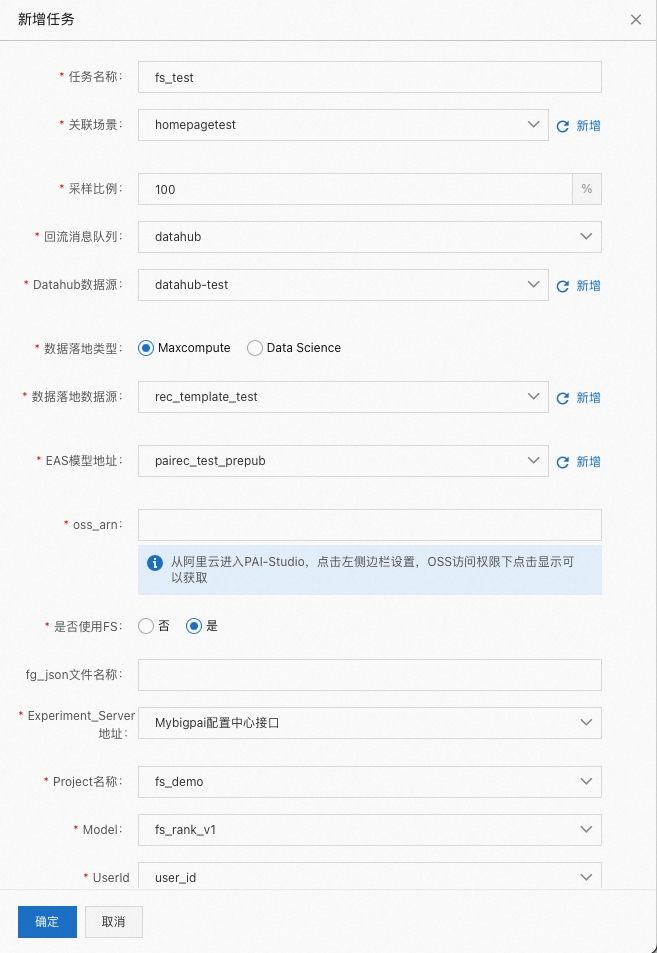
创建完成后点击确定,可看到如下图所示任务:

6.2 运行¶
点击启动任务:

在启动任务中选择场景:
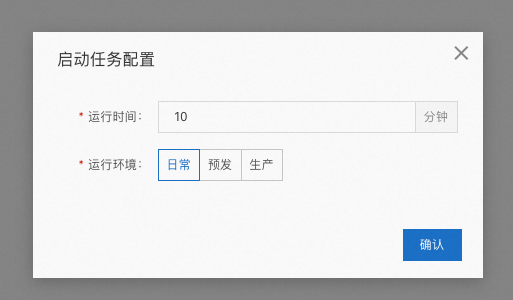
可以根据有流量的场景选择,一般在预发环境中打流量测试。选择完成后点击确认。
确认后,可以在任务日志中查看任务详情:
任务运行完成后,能在任务日志对应的任务中看到结果。
7. 上线¶
测试一致性没有问题后,可以先小流量上线测试,然后再慢慢转为大流量。流量大小可以在推荐引擎 pairec 中设置,设置方法具体可以参考 pairec 文档:
下面给出一个小流量测试的样例步骤: 例如一个小流量观察的步骤:先设置 1% 流量观察 10 分钟,没问题后,设置 2% 流量观察 20 分钟,服务依然正常后,设置 5% 流量观察 30 分钟。如果服务依然正常,说明服务基本稳定,可以先再继续观察一段时间,或者再根据实际情况扩流量观察。