流量模型¶
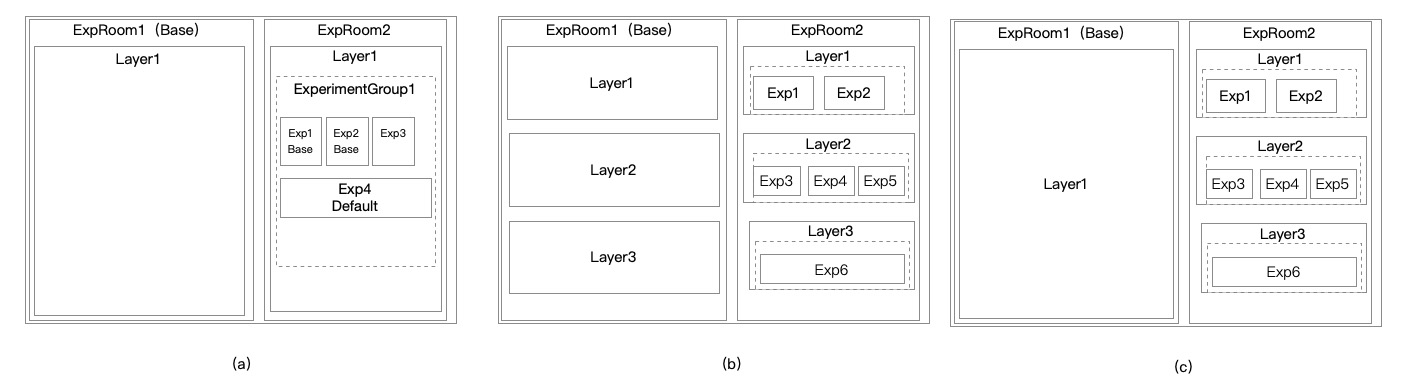
在应用场景中,考虑单层和多层的情况。
(a)是对单层结构的示例。不管是单层多层,没有匹配到实验室的流量都会分配到默认的实验室中。
单层结构是指实验室下只有一层 Layer。 在这层 Layer 下,可以创建多个实验组
多个实验组之间的流量不会相互干扰。
每个实验组包含两类实验,对照组(base), 实验组。
对照组可以设置AA, 也就是会镜像一个实验,用于验证流程的正确性
(b) 是多层结构,具体层的数量,由业务场景决定,并且可以动态调整。每层的流量是完全一样的,都是继承自实验室的流量。同样,在每层可以创建多个实验组,要求与单层是一致的。
(c)不同的实验室可以设置不同的层级结构,有些实验需要在不同的层上做,有些需要拉通整个层来做。
实验组会默认继承所在层的流量,当然也可以设置 filter 条件来选取更细致的流量。
实验级别的流量由系统根据流量占比自动分配,f(uid, exproom, layer, expgroup) % 100 计算得出的桶号,然后匹配实验。
在埋点统计中会记录 exp_id。 exp_id 会记录流程的实验路径。假设(a) 中命中了实验室2中的实验2, exp_id 就是 ER2_L1#EG1#E2。 (b) 中分配到了实验2中,分别命中了 Layer1 的 Exp2, Layer2 的 Exp3, Layer3 的 Exp6, exp_id 就是 ER2_L1#EG1#E2_L2#EG1#E3_L3#EG1#E6。
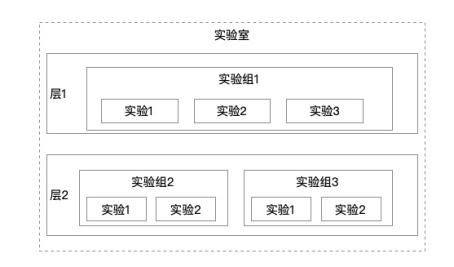
一个实验室下可以包含任意多层,一个层可以理解为一组配置的逻辑组合(不同层之间,配置不应有重合)。层与层之间的流量是正交的。同一个层上,不同实验组之间的流量是互斥的。统计指标是与实验组关联的。最终指标效果是通过实验组下的实验来展现的。不同实验组之间,指标不具备可比性。