特征平台主要功能介绍¶
1. 维持离线数据和在线数据一致¶
表注册到特征平台后,会自动在 online store (holo, igraph, redis) 等创建在线表,供在线读取。
1.1 注册步骤¶
将 mc 表注册到特征平台可以参考教程:
网页操作:特征平台网页操作
Python SDK 操作:特征平台 Python SDK 操作
1.2 数据同步¶
1.2.1 数据同步代码¶
数据同步是指将数据从 offline store (max compute, spark) 同步到 online store (hologres, igraph, redis) 中,在 feature store python sdk 中,数据同步可以通过以下代码来完成:
from feature_store_py.fs_client import FeatureStoreClient
import datetime
cur_day = '20230301'
print("cur_day = ", cur_day)
host = 'http://12345/api/predict/pairec_experiment'
token = 'AAXXXXXBBBBB'
fs = FeatureStoreClient(host, token)
cur_project_name = 'fs_test'
project = fs.get_project(cur_project_name)
feature_view_name = 'fs_feature_view_1'
batch_feature_view = project.get_feature_view(feature_view_name)
task = batch_feature_view.publish_table(partitions={'dt':cur_day}, mode='overwrite')
print(task.summary)
task.wait()
print(task.task_summary)
其中核心代码为:
task = batch_feature_view.publish_table(partitions={'dt':cur_day}, mode='overwrite')
表示将 offline store 中对应分区的数据同步到 online store 中。
1.2.2 数据同步结果¶
数据同步结果可以通过任务中心看到,如下图所示:
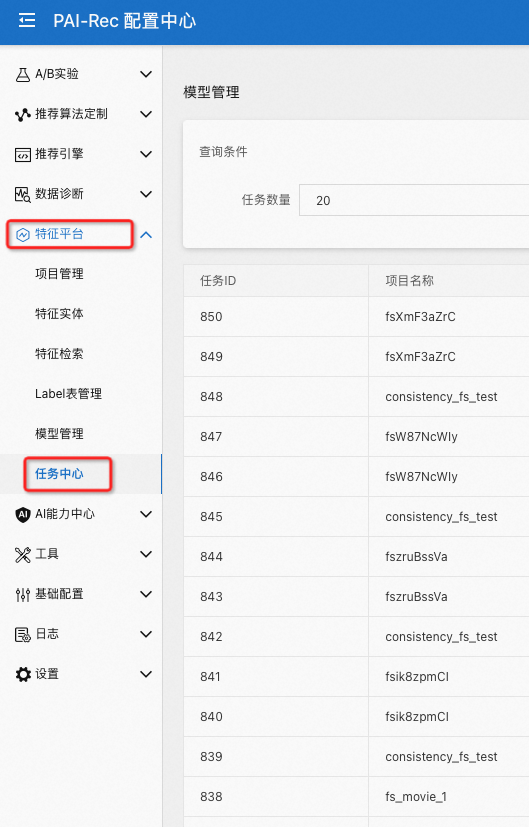
点击任务名称为 offline store 数据同步到 online store 中的任务详情:

在任务运行配置中可以看到实际执行的操作:
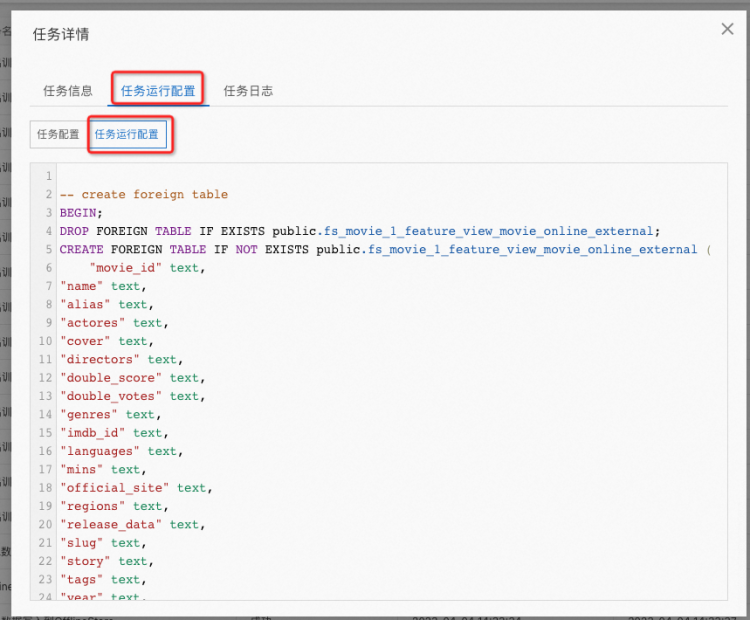
复制粘贴出内容如下所示:
-- create foreign table
BEGIN;
DROP FOREIGN TABLE IF EXISTS public.fs_movie_1_feature_view_movie_online_external;
CREATE FOREIGN TABLE IF NOT EXISTS public.fs_movie_1_feature_view_movie_online_external (
"movie_id" text,
"name" text,
"alias" text,
"actores" text,
"cover" text,
"directors" text,
"double_score" text,
"double_votes" text,
"genres" text,
"imdb_id" text,
"languages" text,
"mins" text,
"official_site" text,
"regions" text,
"release_data" text,
"slug" text,
"story" text,
"tags" text,
"year" text,
"actor_ids" text,
"director_ids" text,
"dt" text
)
SERVER odps_server
OPTIONS (project_name 'pai_rec_dev',table_name 'fs_movie_1_feature_view_movie_offline');
COMMIT;
-- create tmp table
BEGIN;
DROP TABLE IF EXISTS public.fs_movie_1_feature_view_movie_online_tmp;
CREATE TABLE IF NOT EXISTS public.fs_movie_1_feature_view_movie_online_tmp ("movie_id" text primary key,
"name" text,
"alias" text,
"actores" text,
"cover" text,
"directors" text,
"double_score" text,
"double_votes" text,
"genres" text,
"imdb_id" text,
"languages" text,
"mins" text,
"official_site" text,
"regions" text,
"release_data" text,
"slug" text,
"story" text,
"tags" text,
"year" text,
"actor_ids" text,
"director_ids" text
);
call set_table_property('public.fs_movie_1_feature_view_movie_online_tmp', 'orientation', 'row');
COMMIT;
-- insert data from foreign table to tmp table
SET hg_experimental_query_batch_size = 1024;
SET hg_experimental_dml_bulkload_dop = 1;
SET hg_experimental_max_num_record_batches_in_buffer = 16;
SET hg_experimental_odps_executor_max_dop = 8;
SET hg_foreign_table_executor_dml_max_dop = 2;
INSERT INTO public.fs_movie_1_feature_view_movie_online_tmp
SELECT "movie_id",
"name",
"alias",
"actores",
"cover",
"directors",
"double_score",
"double_votes",
"genres",
"imdb_id",
"languages",
"mins",
"official_site",
"regions",
"release_data",
"slug",
"story",
"tags",
"year",
"actor_ids",
"director_ids" from public.fs_movie_1_feature_view_movie_online_external WHERE dt='20220830';
-- remame tmp table to online table
ALTER TABLE public.fs_movie_1_feature_view_movie_online RENAME TO fs_movie_1_feature_view_movie_online_outdate;
ALTER TABLE public.fs_movie_1_feature_view_movie_online_tmp RENAME TO fs_movie_1_feature_view_movie_online ;
DROP TABLE IF EXISTS public.fs_movie_1_feature_view_movie_online_outdate;
可以看到实际是调用了 hologres 的 api, 按照 hologres 的数据同步的方式进行了同步。用几行 python 代码可以完成,节省了工作量。
2. 支持导出表自动关联¶
支持自动将数十张表关联导出,导出时支持序列表导出,支持按 event_time 关联导出,支持自动按表大小排序,优化导出时间。
2.1 任意表关联¶
支持任意多的表关联,可以将 user 特征分散在数十个小表中,将 item 特征分散在数十个小表中,然后导出训练表时,能够自动对任意选择的表进行关联 。
更详细的示例,可以参考下面的介绍。
2.2 支持序列表,支持 event_time 导出¶
2.2.1 Python SDK 中配置方式¶
label_partitions = PartitionConfig(name = 'ds', value = '20221121')
label_input_config = LabelInputConfig(partition_config=label_partitions)
user_partitions = PartitionConfig(name = 'ds', value = '20221120')
feature_view_user_config = FeatureViewConfig(name = 'dwd_user_info_preprocess_all_feature_v1', partition_config=user_partitions)
item_partitions = PartitionConfig(name = 'ds', value = '20221120')
feature_view_item_config = FeatureViewConfig(name = 'dwd_item_info_preprocess_all_feature_v1', partition_config=item_partitions)
seq_partitions = PartitionConfig(name = 'ds', value = '20221121')
feature_view_seq_config = FeatureViewConfig(name = 'dwd_user_sequence_wide_seq_feature_v1', partition_config=seq_partitions, event_time='event_unix_time', equal=True)
feature_view_config_list = [feature_view_user_config, feature_view_item_config, feature_view_seq_config]
train_set_partitions = PartitionConfig(name = 'ds', value = '20221121')
train_set_output_config = TrainSetOutputConfig(partition_config=train_set_partitions)
注意到其中序列特征的指定配置如下:
feature_view_seq_config = FeatureViewConfig(name = 'dwd_user_sequence_wide_seq_feature_v1', partition_config=seq_partitions, event_time='event_unix_time', equal=True)
其中 event_time 字段指定了表中事件时间字段,equal=True 表示序列表中的事件时间等于 label 表中的事件时间,equal=False 表示序列表中的事件时间小于 label 表中的事件时间。
更多的,由于此时 equal=True 表示序列表中的事件时间等于 label 表中的事件时间,因此我们在配置时 event_time 可以不用指的是真正的事件时间,可以是任何需要和 label 表中相等的额外字段。例如有的序列表其 join 关系不是靠 event_time 来 join, 而且依赖序列表中的 request_id 和 label 表中的 request_id 来 join。
2.2.2 运行结果¶
insert overwrite table rec_fs_model_v1_trainning_set partition (ds = '20230403')
select
* (为了示例省略)
from
(
select *
from dwd_label_table_v1
where ds = '20230403'
) sq0
left join (
select
*
from dwd_user_info_preprocess_all_feature_v1
where ds = '20230402'
) sq1 on sq0.userid = sq1.userid
left join (
select
*
from dwd_user_sequence_wide_seq_feature_v1
where ds = '20230403'
) sq3 on sq0.userid = sq3.userid and sq0.event_unix_time = sq3.event_unix_time
left join (
select
*
from dwd_item_info_preprocess_all_feature_v1
where ds = '20230402'
) sq2 on sq0.item_id = sq2.item_id
;
2.2.3 扩展¶
更多的,由于此时 equal=True 表示序列表中的事件时间等于 label 表中的事件时间,因此我们在配置时 event_time 可以不用指的是真正的事件时间,可以是任何需要和 label 表中相等的额外字段。例如有的序列表其 join 关系不是靠 event_time 来 join, 而且依赖序列表中的 request_id 和 label 表中的 request_id 来 join,此时的 event_time 就可以用来指 request_id 。如下所示:
feature_view_seq_config = FeatureViewConfig(name = 'ali_rec_rebuild_seq_feature', partition_config=seq_partitions, event_time='request_id', equal=True)
运行结果如下所示:
insert overwrite table rec_fs_homepage_rank_v1_trainning_set partition (dt = '20230215')
* (为示例省略)
from
(
select *
from homepage_raw_rank_samples
where dt = '20230215'
) sq0
left join (
select
*
from user_basic_feature
where dt = '20230214'
) sq1 on sq0.client_str = sq1.client_str
left join (
select
*
from ali_rec_rebuild_seq_feature
where dt = '20230215'
) sq4 on sq0.client_str = sq4.client_str and sq0.request_id = sq4.request_id
left join (
select
*
from user_statistical_feature
where dt = '20230214'
) sq2 on sq0.client_str = sq2.client_str
left join (
select
*
from item_all_feature
where dt = '20230214'
) sq3 on sq0.style_id = sq3.style_id
;
其中的序列表 ali_rec_rebuild_seq_feature 就是依靠 request_id 与 label 表 homepage_raw_rank_samples 进行关联。
2.3 支持优化导出时间¶
2.3.1 实现原理¶
在运行导出的 sql 时,发现 max compute 是会根据 join 的前两个表来分配运行的资源,这样在用代码拼出sql 的时候,会在 label 外,读取 user 表 和 item 表的对应分区的数据大小 size,将所有的 user 表 和 item 表按照 size 进行排序,从大到小进行 join 。第一个表是 label 表,其余的表按 size 从大到小进行 join, 能够提高最多 50% 的运行时间。
2.3.2 查看实现的 sql¶
在特征平台中点击 任务中心,再点击右边的详情,如下图所示:
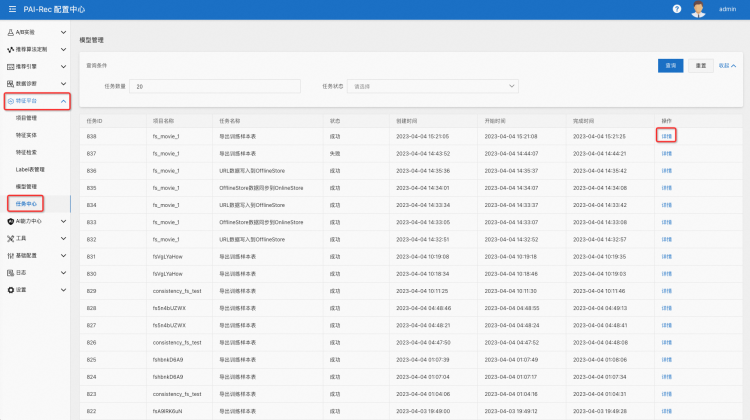
在详情中点击 任务运行配置,再点击下方的任务运行配置,即可看到自动生成的 sql, 如下所示:
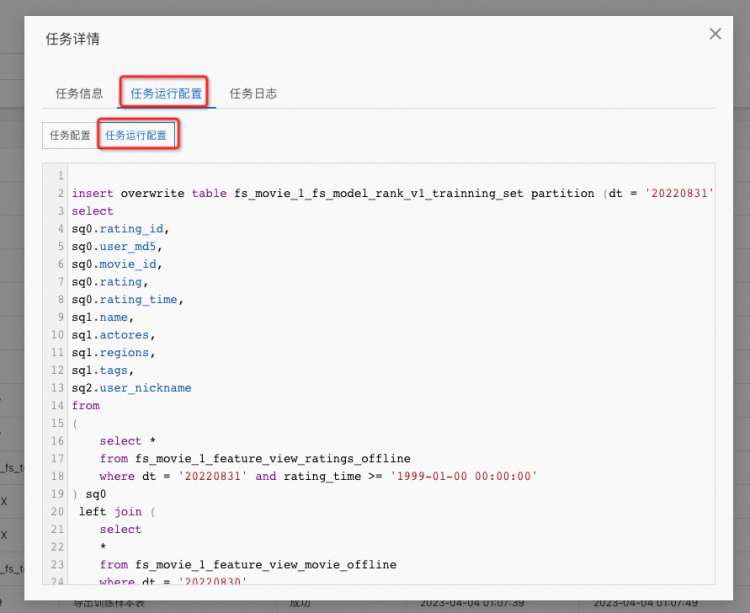
将示例的 sql 复制粘贴出来如下:
insert overwrite table fs_movie_1_fs_model_rank_v1_trainning_set partition (dt = '20220831')
select
sq0.rating_id,
sq0.user_md5,
sq0.movie_id,
sq0.rating,
sq0.rating_time,
sq1.name,
sq1.actores,
sq1.regions,
sq1.tags,
sq2.user_nickname
from
(
select *
from fs_movie_1_feature_view_ratings_offline
where dt = '20220831' and rating_time >= '1999-01-00 00:00:00'
) sq0
left join (
select
*
from fs_movie_1_feature_view_movie_offline
where dt = '20220830'
) sq1 on sq0.movie_id = sq1.movie_id
left join (
select
*
from fs_movie_1_feature_view_users_offline
where ds = '20220830'
) sq2 on sq0.user_md5 = sq2.user_md5
;
可以检查到表:fs_movie_1_feature_view_movie_offline 在 dt = ‘20220830’ 中的数据量是大于等于表:fs_movie_1_feature_view_users_offline 在 ds = ‘20220830’ 中的数据量的。
3. Feature Store Python SDK¶
Feature Store Python SDK 支持所有接口,可以直接安装 pip 包后以 python 代码方式使用。
部分可参考:特征平台 Python SDK 操作,先按 python sdk 操作走完全流程后,就可以运行下面的特征分析。
3.1 获取线上特征分析¶
可以获取 online store (hologres, igraph, redis 等) 中的特征用于分析:
feature_view_movie_name = "feature_view_movie"
batch_feature_view = project.get_feature_view(feature_view_movie_name)
ret_features_1 = batch_feature_view.get_online_features(join_ids={'movie_id':['26357307']}, features=['name', 'actores', 'regions'])
print("ret_features = ", ret_features_1)
其中 feature_view_movie_name 就是指注册在特征平台的特征视图名字,’movie_id’ 指的是主键,features 指的是想要查看的特征名称。
4. 自动根据 model 分析出所需要的特征,自动加载¶
在 EAS 侧和 PAIREC 引擎侧可以自动根据 feature store model 分析出使用的特征,自动加载相关特征。
4.1 EAS 侧¶
EAS 侧配置主要是用来拉取 item 侧特征。一般配置时需指定特征平台相关的特征,以及创建的 project 和 model, 具体配置示例如下所示:
"model_config": {
"fg_mode": "tf",
"fs_host": "http://xxx.vpc.xxx",
"fs_token": "xxx",
"fs_entity": "item",
"fs_model": "fs_model_v1",
"fs_project": "demo_rec",
"outputs": "probs",
"period": 2880,
"prefetch_feature_hot_ids": true,
"steady_mode": true
},
其中 fs_host 和 fs_token 指定了特征平台 server 端的信息,fs_model 指定了创建的模型名称,fs_entity 指定了需要拉取的特征的 entity 。在这里指定的 fs_entity 是 “item”, 即使有数十张 item 表组成了 model, 这里也可以自动获取数十张表的信息拉取到 EAS 内存中。
4.2 PAIREC 引擎侧¶
PAIREC 引擎侧配置主要是用来拉取 user 侧特征。一般配置时需指定特征平台地址,以及创建的 project 和 model 相关的信息。具体配置如下所示:
配置 server 端地址:
"FeatureStoreConfs": {
"pairec-fs": {
"Host": "xxx",
"Token": "xxx",
"ProjectName": "demo_rank"
}
},
配置特征平台 model 名称和 entity 名称。
"rank_v1": {
"AsynLoadFeature": true,
"FeatureLoadConfs": [
{
"FeatureDaoConf": {
"AdapterType": "featurestore",
"FeatureStoreName": "pairec-fs",
"FeatureKey": "user:uid",
"FeatureStoreModelName": "rank_v1",
"FeatureStoreEntityName": "user",
"FeatureStore": "user"
},
}
]
},
其中 FeatureStoreModelName 指定了特征平台中的模型名称,FeatureStoreEntityName 指定了 entity 名称。这里指定的 entity 名称是 “user”, 即会拉取所有挂在名为 “user” 的 entity 的特征表。不再需要指定具体的特征名。
5. 支持 EAS 缓存加载部分热门 item_id¶
支持 EAS 缓存,支持加载部分特征到 EAS 内存。线上请求时,会优先查询缓存中的特征,没有查到时再去 online store (holo, igraph, redis) 查询。
5.1 计算热门 item_id¶
可以计算过往 3 天出现过的 item_id 作为热门 item_id.
create table if not exists hot_item_ids_table
(
item_id STRING
)
PARTITIONED by (dt STRING)
LIFECYCLE 30;
insert overwrite table hot_item_ids_table partition (dt = '${bdp.system.bizdate}')
SELECT
distinct item_id
from all_item_features_v1
where dt = '${bdp.system.bizdate}' and item_id in (
select item_id
from label_table_v1
WHERE dt > TO_CHAR(DATEADD(TO_DATE('${bdp.system.bizdate}','yyyymmdd'), - 3,'dd'),'yyyymmdd')
and dt <= '${bdp.system.bizdate}'
);
上图所展示的是从 item 表中 all_item_features_v1 取出过往 3 天出现在 label 表:label_table_v1 中的 item_id 作为热门 item_id 。
5.2 导入热门 item_id¶
from odps import ODPS
import sys
import feature_store_py
from feature_store_py.fs_client import FeatureStoreClient
from feature_store_py.fs_project import FeatureStoreProject
from feature_store_py.fs_datasource import OSSDataSource, MaxComputeDataSource, DatahubDataSource, HologresDataSource, SparkDataSource, LabelInput
print('dt = ' + args['dt'])
host = "xxxxx"
token = "xxxxx"
fs = FeatureStoreClient(host, token)
cur_project_name = "demo_rank"
offline_datasource_id = 2
online_datasource_id = 6
project = fs.get_project(cur_project_name)
project.print_summary()
version = args['dt']
version += "__hot_ids_new_v3"
cur_entity_name = 'item'
print("version = ", version)
t = o.get_table('hot_item_ids_table')
hot_item_ids = set()
with t.open_reader(partition='dt={}'.format(args['dt'])) as reader:
for i, row in enumerate(reader):
for record in row:
if record[0] == 'item_id':
hot_item_ids.add(record[1])
if i % 100 == 0:
cur_list = list(hot_item_ids)
data = project.write_hot_ids(cur_entity_name, version, cur_list)
print("data = ", data, ", i = ", i)
hot_item_ids = set()
cur_list = list(hot_item_ids)
data = project.write_hot_ids(cur_entity_name, version, cur_list)
print("data = ", data, ", i = ", i)
hot_item_ids = set()
data2 = project.change_hot_ids_version(cur_entity_name, version)
print("data2 = ", data2)
其中 host, token 指定了配置中心 server 端的地址。第 23 行是利用 pyodps 读取热门 item 表,第 30 行是利用 feature store python sdk 的接口将读取的热门 item_id 存入到 feature store 对应的 version 中。第38行是使存入的 version 生效。
5.3 线上服务¶
当有一个线上请求来请求 EAS 服务时,在读取 item 特征的阶段,会首先判断缓存 (cache) 中有没有该 item id 的特征,有的话会直接读取,没有的话会直接读取 online store (hologres, igraph, redis 等) 存到缓存中,下一次再有相同的请求过来会直接从缓存中读取。
6. 支持实时特征表¶
支持实时特征表,注册为实时特征表时,线上来请求,会实时去 online store (holo, igraph, redis)查询。
6.1 实时特征表注册¶
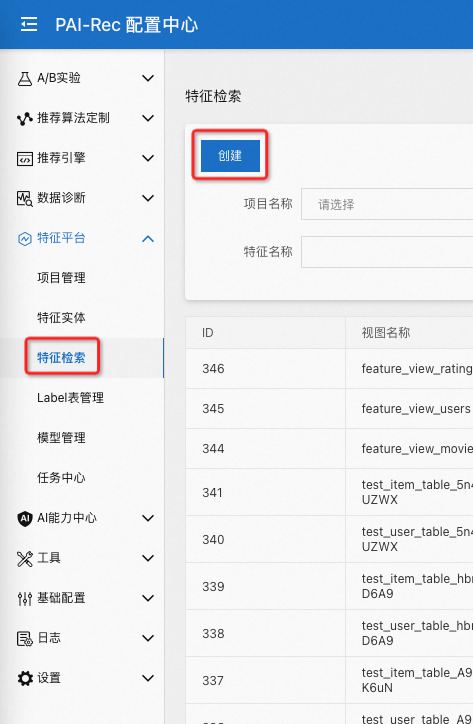
首先点击特征检索里面的创建:
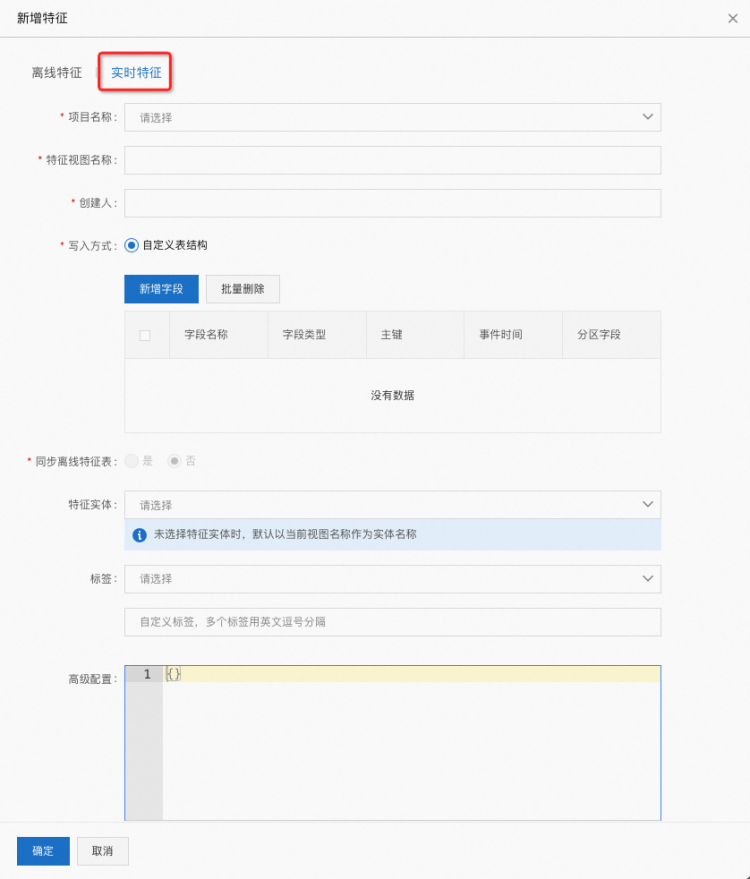
在创建的页面里面选择实时特征:
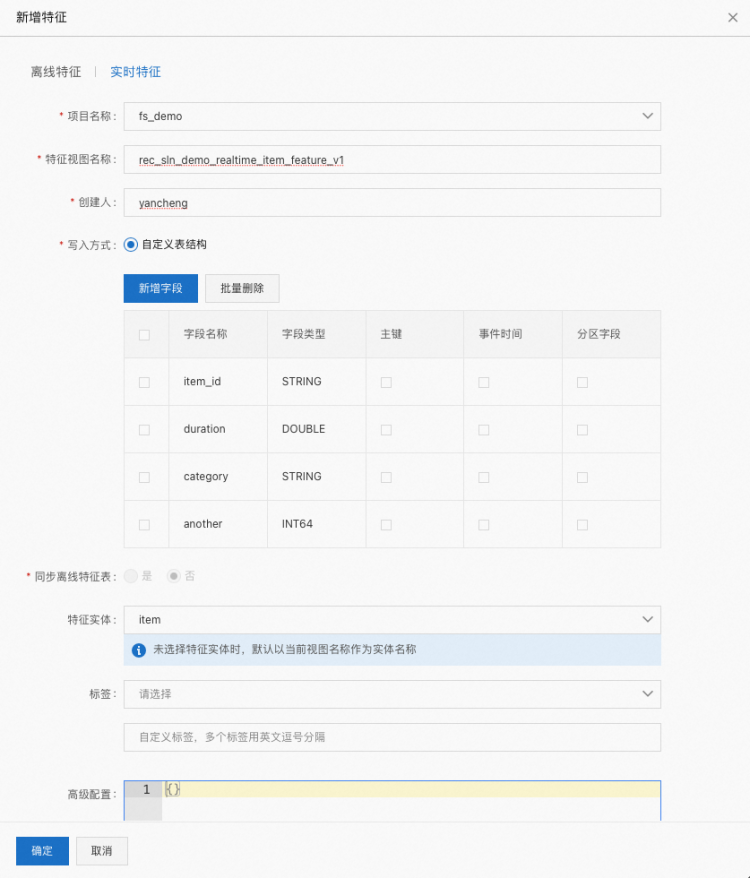
然后填入所示字段,示例如下:
点击确定,创建完成后如下图所示:
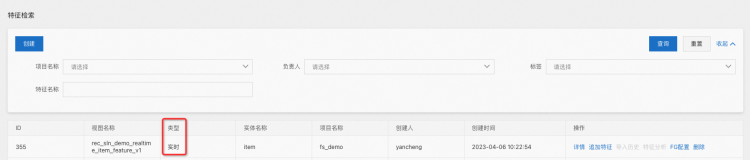
其中类型会显示为实时。
6.2 线上服务¶
当有线上请求时,读取 item 特征时会判断一下这部分特征是不是实时特征,不是实时特征会按照缓存的方式读取,是实时特征时会直接读取 online store (hologres, igraph, redis)。
7. 推荐算法定制初次部署时支持选择特征平台¶
推荐算法定制初次部署时支持选择特征平台。
7.1 config 配置¶
首先需要在 workspace 配置中添加 feature store 的配置:
workspace: {
feature_store {
host: "${host}"
token: "${token}"
project_name: "${project_name}"
model_name: "${model_name}"
offline_datasource_id: 1
online_datasource_id: 2
}
}
然后在 feature config 和 rank config 中设置 feature_store = True, 即可自动将生成的表导入到 feature store 中。
7.2 部署运行步骤讲解¶
主要是分为两大部分:特征同步,train set 导出。
7.2.1 特征同步¶
特征同步阶段,会针对 item 特征 和 user 特征,分别自动生成一个 pyodps 节点,节点内容示例如下:
from feature_store_py.fs_client import FeatureStoreClient
import datetime
def getdate(beforeOfDay):
today = datetime.datetime.now()
# 计算偏移量
offset = datetime.timedelta(days=-beforeOfDay)
# 获取想要的日期的时间
re_date = (today + offset).strftime('%Y%m%d')
return re_date
cur_day = getdate(1)
print("cur_day = ", cur_day)
host = 'http://12345/api/predict/pairec_experiment'
token = 'AAXXXXXBBBBB'
fs = FeatureStoreClient(host, token)
cur_project_name = 'fs_test'
project = fs.get_project(cur_project_name)
feature_view_name = 'fs_feature_view_1'
batch_feature_view = project.get_feature_view(feature_view_name)
if batch_feature_view is None:
ds = MaxComputeDataSource(data_source_id=offline_datasource_id, table=table_name)
batch_feature_view = project.create_batch_feature_view(
name='fs_feature_view_1',
owner='RecTemplate',
datasource=ds,
online=True,
entity='user',
primary_key='user_id',
register=True)
task = batch_feature_view.publish_table(partitions={'dt':cur_day}, mode='overwrite')
print(task.summary)
task.wait()
print(task.task_summary)
第 15 行指定了配置中心 server 端地址。第22行是先读取默认设置的特征视图,第一次运行如果没有的话会自动进行创建 (第 25 行),然后第 33 行进行特征同步,将数据由 offline store (max compute, spark) 同步到 online store (hologres, igraph, redis) 中。
7.2.2 train set导出¶
train set 导出阶段,会自动生成一个 pyodps 节点,替换推荐算法定制中原来的 rank_sample 表,节点内容示例如下:
from feature_store_py.fs_client import FeatureStoreClient
from feature_store_py.fs_project import FeatureStoreProject
from feature_store_py.fs_datasource import LabelInput, MaxComputeDataSource, TrainingSetOutput
from feature_store_py.fs_features import FeatureSelector
from feature_store_py.fs_config import LabelInputConfig, PartitionConfig, FeatureViewConfig
from feature_store_py.fs_config import TrainSetOutputConfig, EASDeployConfig
import datetime
cur_day = args['dt']
print('cur_day = ', cur_day)
offset = datetime.timedelta(days=-1)
pre_day = (datetime.datetime.strptime(cur_day, "%Y%m%d") + offset).strftime('%Y%m%d')
print('pre_day = ', pre_day)
host = 'http://12345/api/predict/pairec_experiment'
token = 'AAXXXXXBBBBB'
fs = FeatureStoreClient(host, token)
cur_project_name = 'fs_test'
project = fs.get_project(cur_project_name)
if project is None:
print("start create project")
project = fs.create_project('fs_test', 0, 0)
user_entity_id = project.get_entity('user')
if user_entity_id is None:
print("start create user_entity")
user_entity_id = project.create_entity(name='user', join_id='user_id')
item_entity_id = project.get_entity('item')
if item_entity_id is None:
print("start create item_entity")
item_entity_id = project.create_entity(name='item', join_id='item_id')
user_feature_view = project.get_feature_view('user_feature_table')
if user_feature_view is None:
print("start create user_feature_view")
ds = MaxComputeDataSource(data_source_id=0, table='user_feature_table')
project.create_batch_feature_view(name='user_feature_table',owner='RecTemplate',datasource=ds,online=True,entity='user',primary_key='user_id',register=True)
item_feature_view = project.get_feature_view('item_feature_table')
if item_feature_view is None:
print("start create item_feature_view")
ds = MaxComputeDataSource(data_source_id=0, table='item_feature_table')
project.create_batch_feature_view(name='item_feature_table',owner='RecTemplate',datasource=ds,online=True,entity='item',primary_key='item_id',register=True)
label_partitions = PartitionConfig(name = 'dt', value = cur_day)
label_input_config = LabelInputConfig(partition_config=label_partitions)
user_partitions = PartitionConfig(name = 'dt', value = pre_day)
feature_view_user_config = FeatureViewConfig(name = 'user_feature_table',
partition_config=user_partitions)
item_partitions = PartitionConfig(name = 'dt', value = pre_day)
feature_view_item_config = FeatureViewConfig(name = 'item_feature_table',
partition_config=item_partitions)
feature_view_config_list = [feature_view_user_config, feature_view_item_config]
train_set_partitions = PartitionConfig(name = 'dt', value = cur_day)
train_set_output_config = TrainSetOutputConfig(partition_config=train_set_partitions)
model_name = 'fs_model1'
cur_model = project.get_model(model_name)
if cur_model is None:
print("start create model")
output_ds = MaxComputeDataSource(data_source_id=0)
train_set_output = TrainingSetOutput(output_ds)
user_fea_list = FeatureSelector('user_feature_table', '*')
item_fea_list = FeatureSelector('item_feature_table', '*')
feature_select_list = [user_fea_list, item_fea_list]
label_table = project.get_label_table('test_label_table')
if label_table is None:
print("start create label table")
label_ds = MaxComputeDataSource(data_source_id=0, table = 'test_label_table')
label_table = project.create_label_table('RecTemplate', label_ds)
train_set = project.create_training_set(train_set_output=train_set_output, feature_selectors=feature_select_list, \
label_table_name='test_label_table')
deploy_config = EASDeployConfig(ak_id='', region='', config='')
cur_model = project.create_model(model_name, 'RecTemplate', train_set, deploy_config)
task = cur_model.export_train_set(label_input_config, feature_view_config_list, train_set_output_config)
task.wait()
print("task_summary = ", task.task_summary)
其中第 9 行到第 13 行是读取了当前日期和前一天的日期。第 16 行到第 17 行是配置中心 server 端的相关信息。 第 20 行到第 23 行是先读取 project, 没有的话会先创建 project,第25行到第31行是读取和创建 user_entity 和 item_entity, 第 33 行到第 41 行是读取和创建 feature view。第 44 行到第 56 行是配置导出的分区信息,第59行到第 76 行是读取和创建 model, 第 77 行是 train set 导出。
8. 离在线一致性检查工具支持特征平台¶
离在线一致性检查工具支持特征平台。上线模型时,可通过离在线一致性检查来检查整个推荐流程的一致性。 离在线一致性的文档见: ,以下展示使用特征平台的示例。
8.1 config 配置¶
首先在工具的一致性检查页面选择特征一致性,然后点新增:
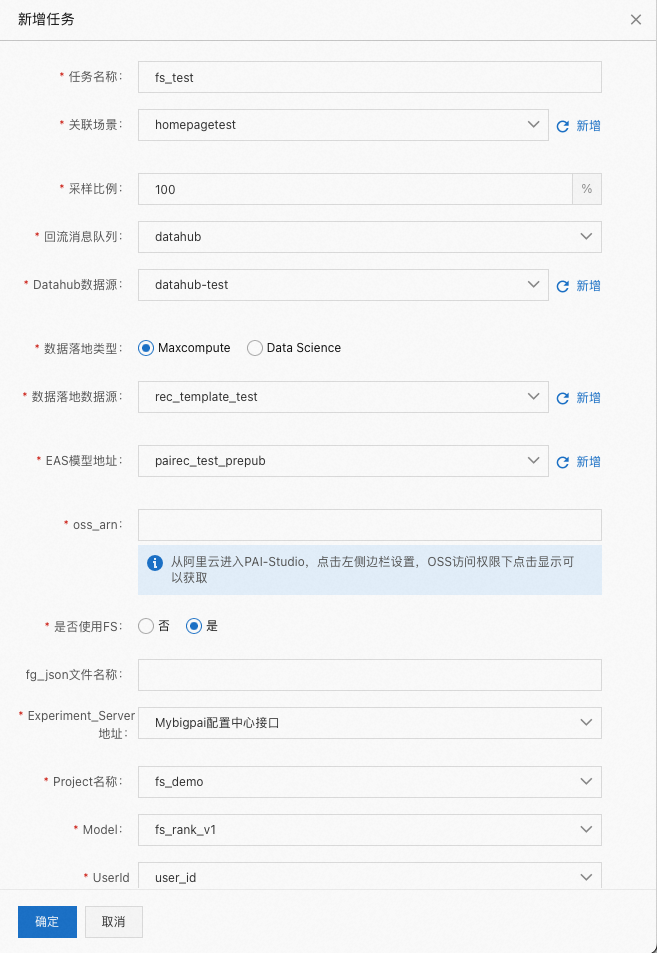
在是否使用 FS 时选择 是,如下图所示:
创建完成后点击确定,可看到如下图所示任务:

8.2 运行步骤讲解¶
前端填入project name 和 model_name, 需要由 feature store python sdk 根据 model_name 分析出所需要的 item 特征表名称,user 特征表名称 以及对应的特征名称, 然后推荐算法定制内拿到 item 特征表名称,user 特征表名称 以及对应的特征名称后,加入目标表,重新传入 feature store python sdk, 运行导出得到 train set 表,然后接下来的流程与原有流程一样,正常过 fg, 运行 easyrec predict 得到离线打分,和在线打分对比。
9. 支持 EAS 缓存直接从 Max Compute 拉取特征,减少在线存储压力¶
目前 LaRec 选择使用 Feature Store 时,其内部的 feature store cpp sdk 可以根据参数直接从 Max Compute 拉取对应时间分区的特征,从而可以减少在线存储的压力。
在 LaRec 中相关的配置参数为:
"model_config": {
"fg_mode": "tf",
"fs_entity": "item",
"fs_host": "http://xxxxxxx",
"fs_model": "fs_rank_v1",
"fs_project": "rec_v1",
"fs_token": "xxxxxx",
"load_feature_from_offlinestore": true,
"outputs": "probs_is_click",
"period": 1440,
"prefetch_feature_hot_ids": false,
"steady_mode": true
}
目前在大规模场景中实际测试,使用 feature store 后:
内存占用:实际测试原有特征需要占据 57 G 内存的情况下,预计可以节省 25G 的内存,由于 LaRec 内部集成的 feature store cpp sdk 有针对存储特征的优化,这种情况下特征占用越多,存储节省的越明显。可以减少资源占用。
拉取特征时间:原来从在线存储 (Hologres, Graph Compute 等)拉取 item 特征到 EAS 缓存改为从 Max Compute 直接拉取 item 特征到 EAS 缓存,实际测试从 21 分钟可以缩减到 4 分钟,并且由于 Max Compute 鲁棒性更好,实际测试可以同时扩容拉起 50 个 EAS 实例, 并且每个实例都可以在 10 分钟左右内加载完所有特征。这样扩容时就不会给在线存储带来很大压力。
模型打分耗时:模型打分时需要实时从缓存取特征,这一方面由于 feature store cpp sdk 有特别的优化,实际测试在使用 feature store 的情况下,tp100 比起之前更优,打分波动更小, 超时请求更少。