AB实验¶
概述¶
A/B 实验是指在在同一时间维度将用户分成几组,在保证每组用户特征相同的前提下,让用户分别看到不同的方案设计,根据数据指标的反馈来科学决策到底采用哪种方案。 在推荐场景中,A/B 实验是算法或策略能做到快速敏捷迭代最不可或缺的一环,可以助力推荐的算法和策略效果能科学稳步地往前迭代。 下面会基于示例数据来具体讲解下怎么使用PAI A/B实验工具。
术语¶
A/B实验后续会涉及到的一些术语,这边先做下简要的介绍,详细可以参考使用手册
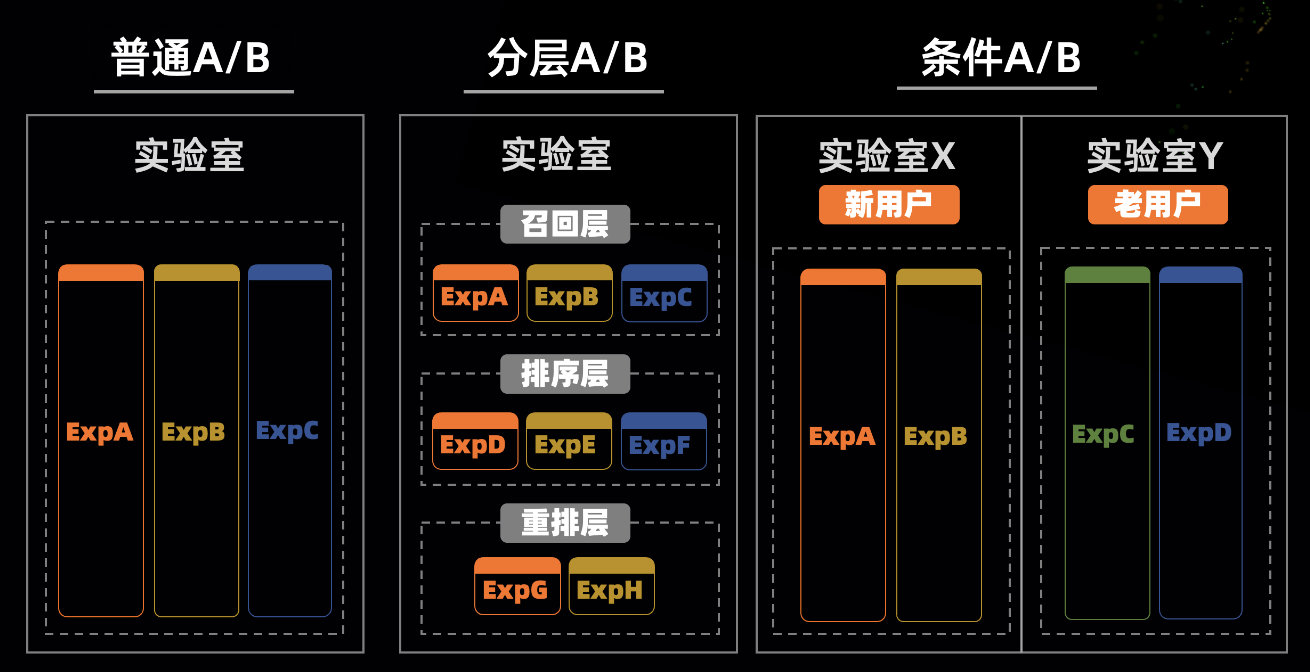
实验室:是场景下流量的集合。可以根据 uid 尾号 或者 uid hash 尾号来进行流量划分,也可以根据具体的业务条件用表达式进行划分,如新老用户等
层: 实验室下面可以包含一个或多个层。每层的流量是正交的,并承载了所在实验室的所有流量,因此可以做到的高效的流量复用
实验组 & 实验:在层上做的实验会由实验组来组织,一个层下面可以包含多个实验组,并且实验组上也可以设置过滤条件来选择实验组中的实验作用在部分流量上。实验组里可以包含 AA, AB等实验,实验本质上是管理的是一组实验参数,控制走不同的算法策略。
通过实验室/层/实验组/实验组的组织可以满足如下多样化的A/B需求
使用流程¶
A/B实验配置与上线¶
本小节主要通过上线一个简单的调整排序模型打分融合的A/B实验来讲解如何配置和上线A/B实验
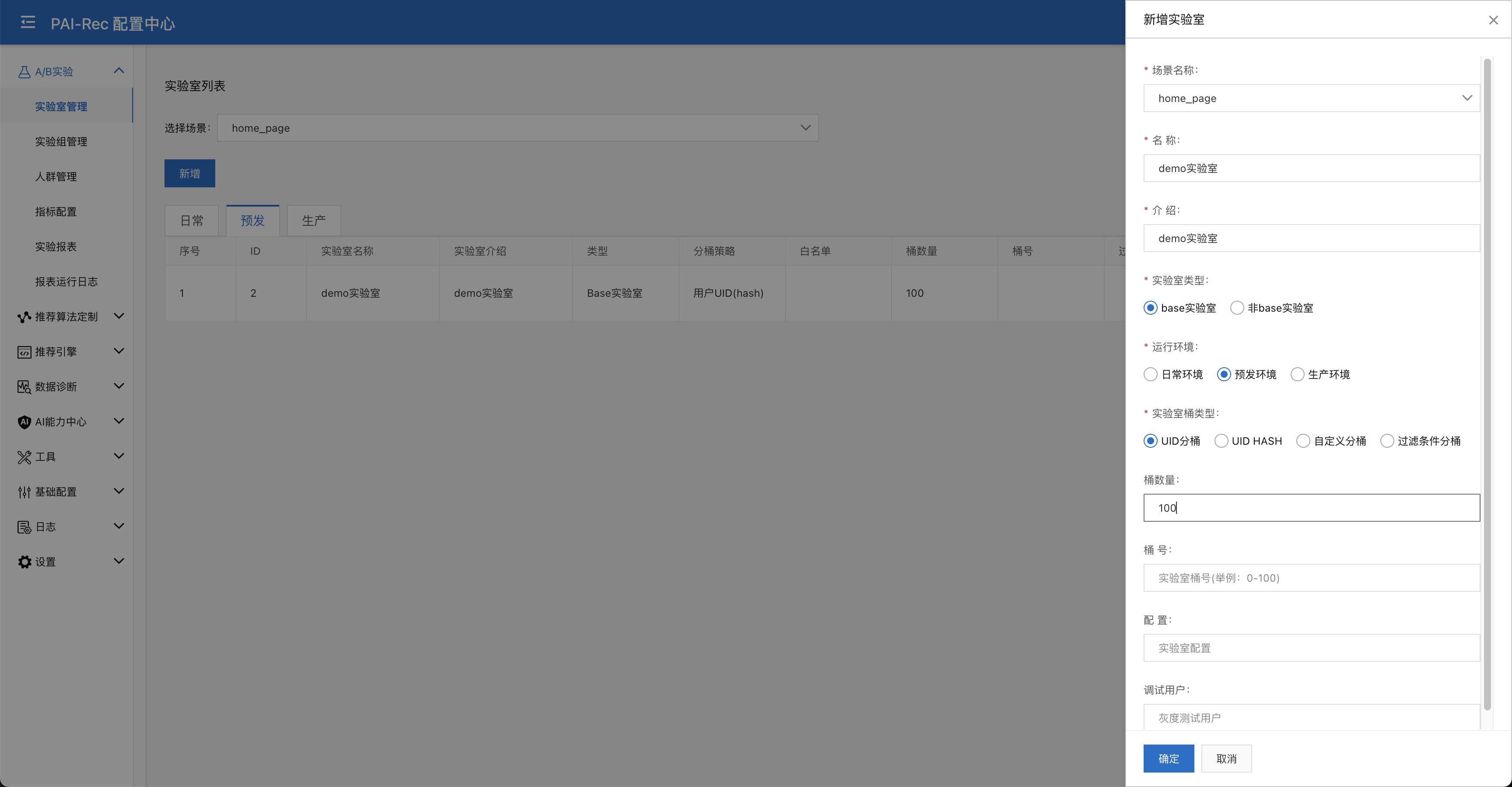
新增实验室:进入运维与实验操作台的A/B实验 > 实验室管理 > 预发环境点击新增一个实验室,场景选择home_page,实验室类型选择base实验室,实验室桶类型选择UID HASH
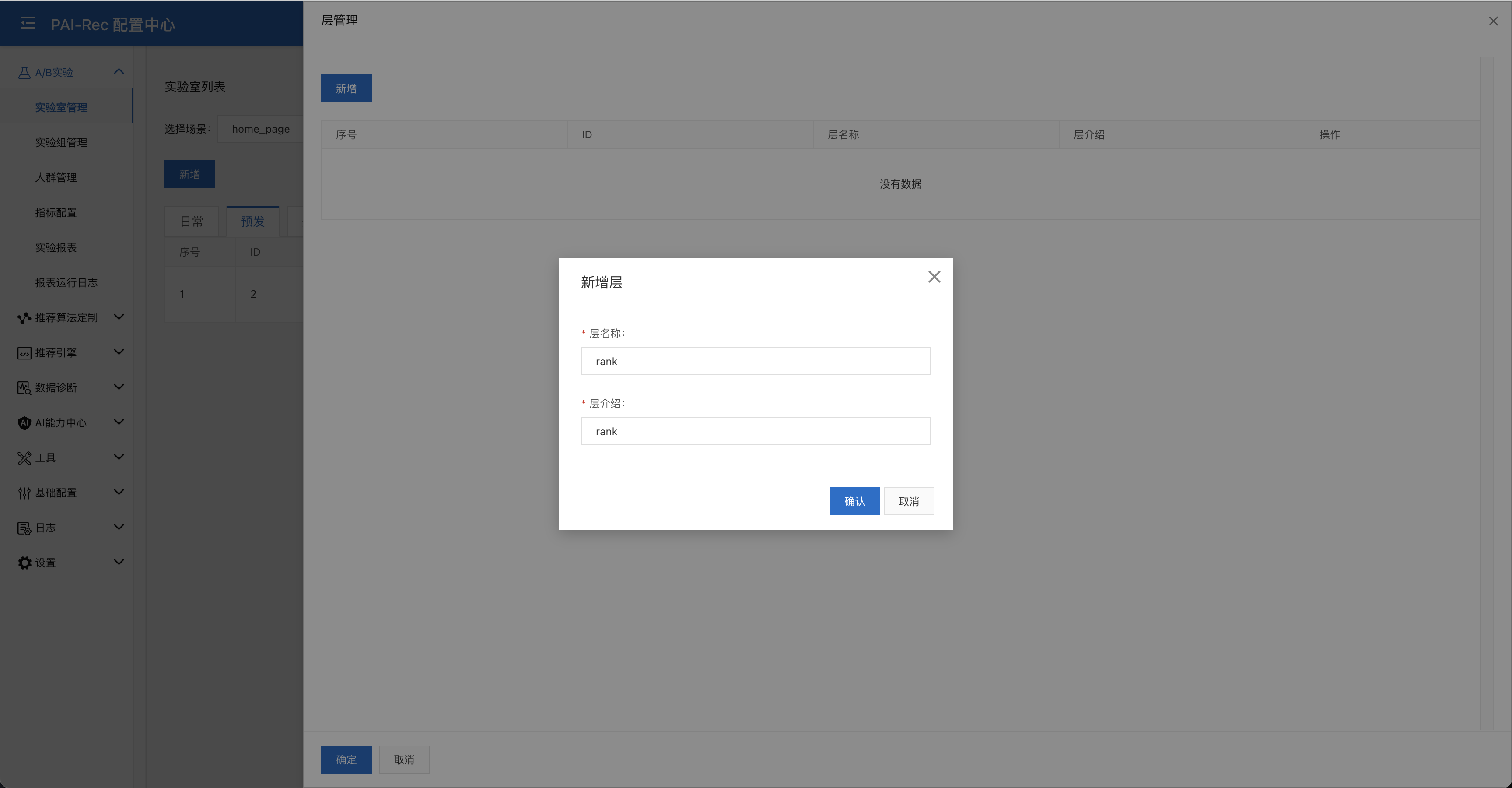
新增层:点击预发环境demo实验室上的层管理新增一个rank层
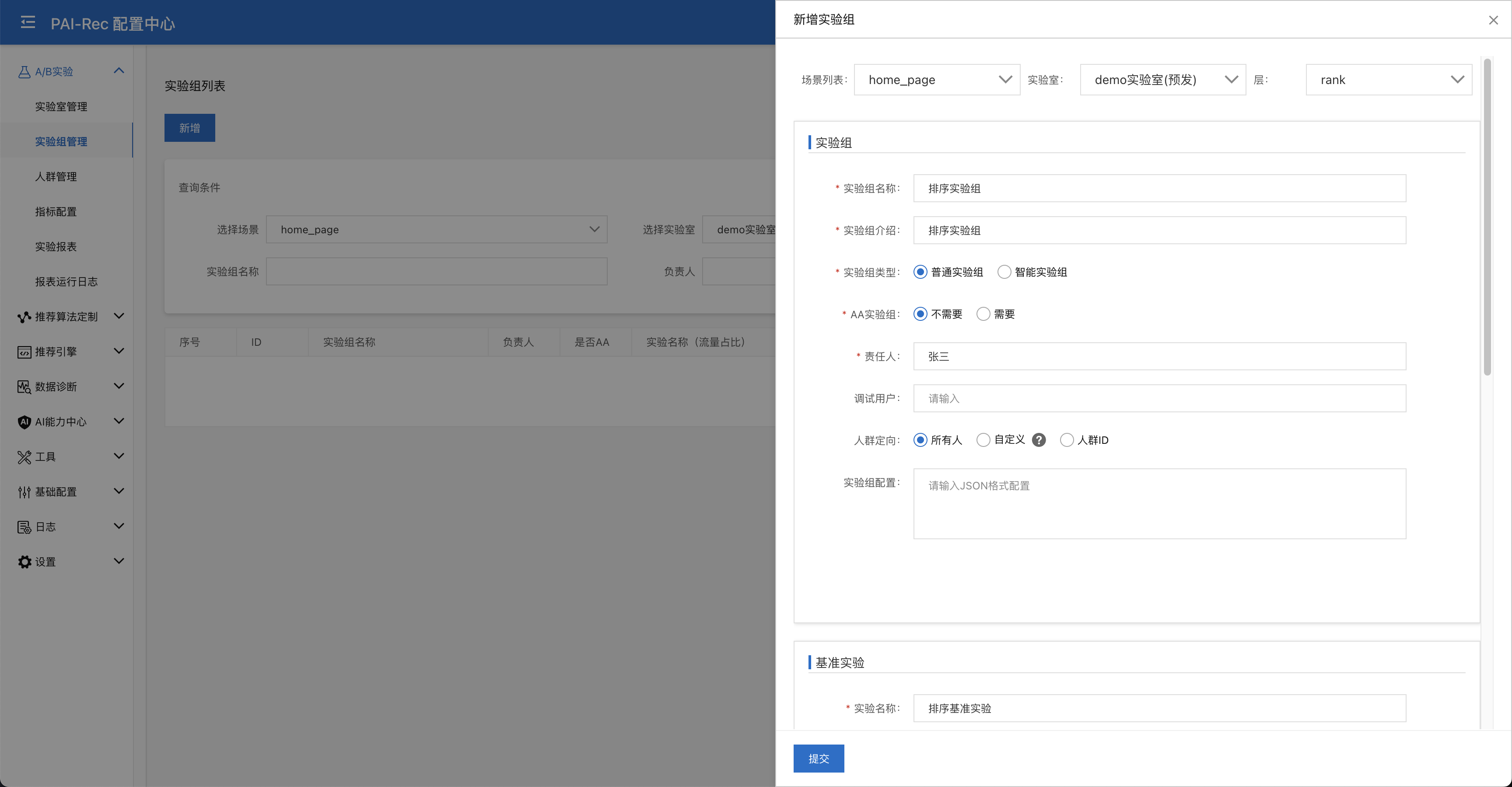
新增实验组:进入A/B实验 > 实验组管理页面,点击新增按钮,在home_page场景 - demo实验室(预发)- rank层下新增一个实验组。包含一个基准实验,其中实验配置为空,也就是跟前文中的推荐算法配置中保持一致;同时包含一个对照实验,我们将is_click目标的打分设置为原来的10倍做一个演示,详细的实验配置参考附录A,并在对照实验上绑定一个调试用户,方便后面调试实验是否生效。
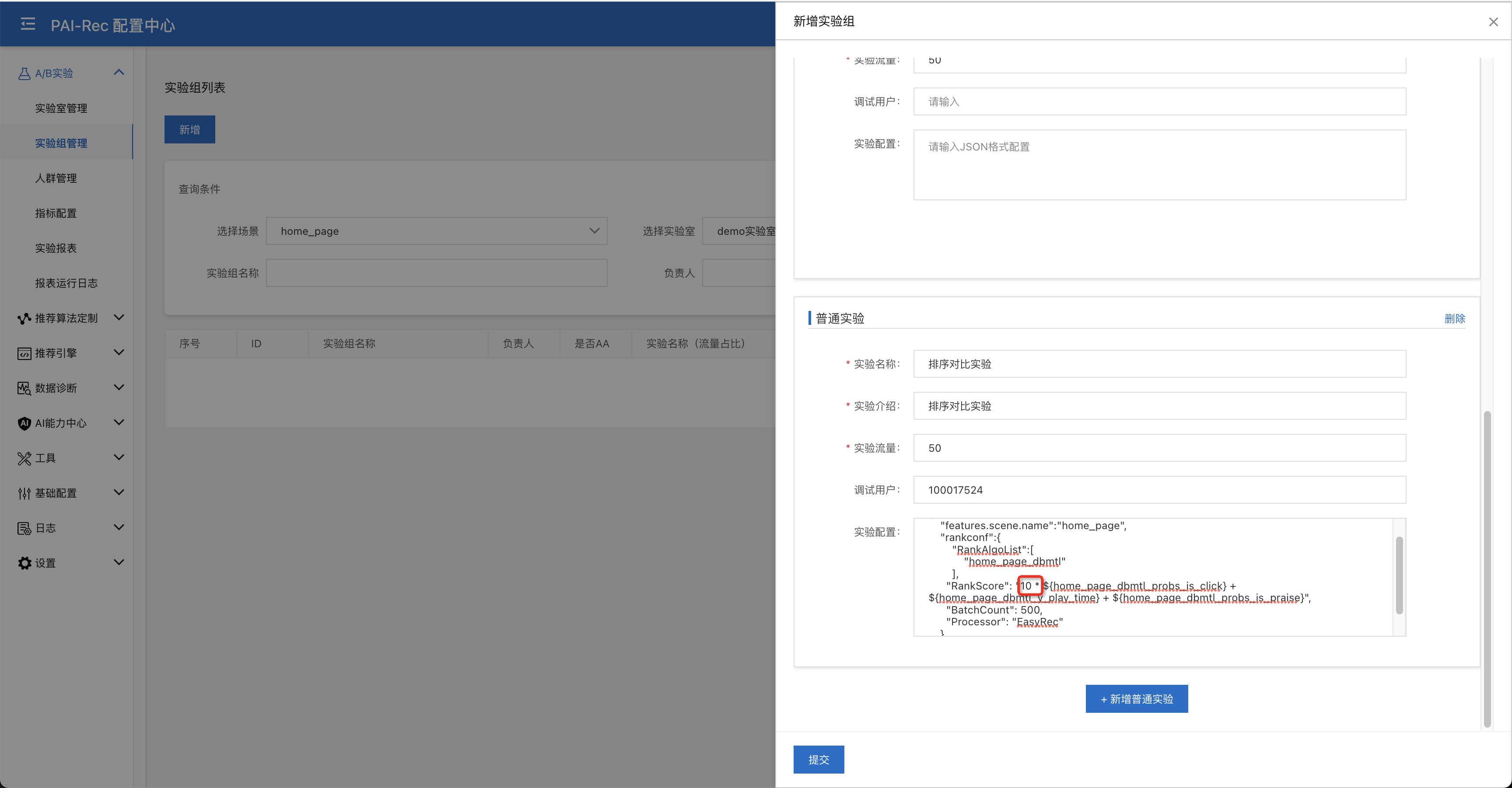
上线实验:创建好了实验室/实验组/实验,我们要分别对实验室/实验组/实验执行上线操作
进入A/B实验 > 实验室管理 > 预发页面,选择home_page场景的demo实验室,点击上线按钮
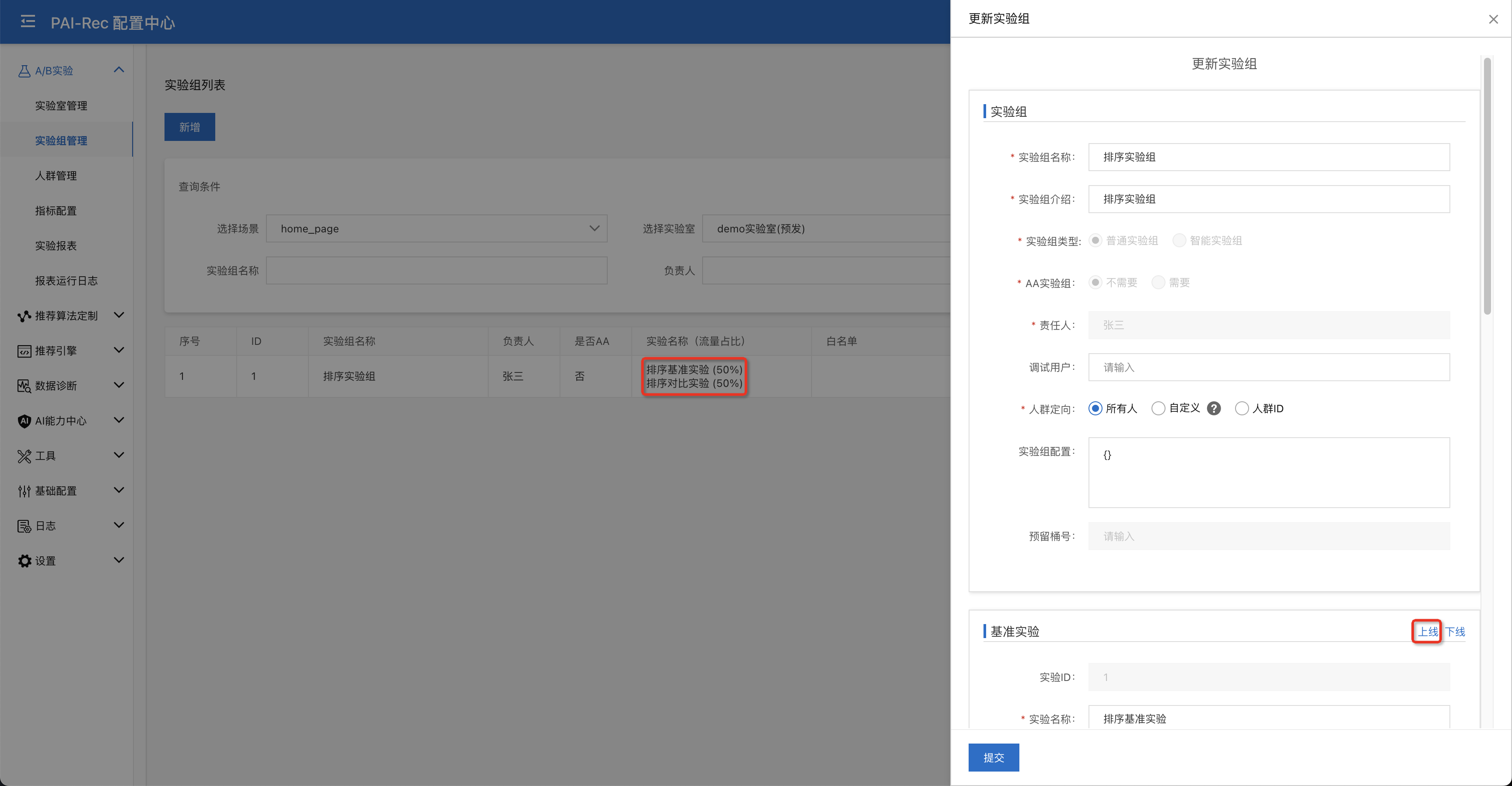
进入A/B实验 > 实验组管理页面在home_page场景 - demo实验室(预发)- rank层下,选择排序实验组,点击上线按钮
选择排序实验组,点击更新按钮,分别将排序基准实验和排序对照实验进行上线,上线完成后我们可以在实验组页面上看到每个实验各自的流量占比
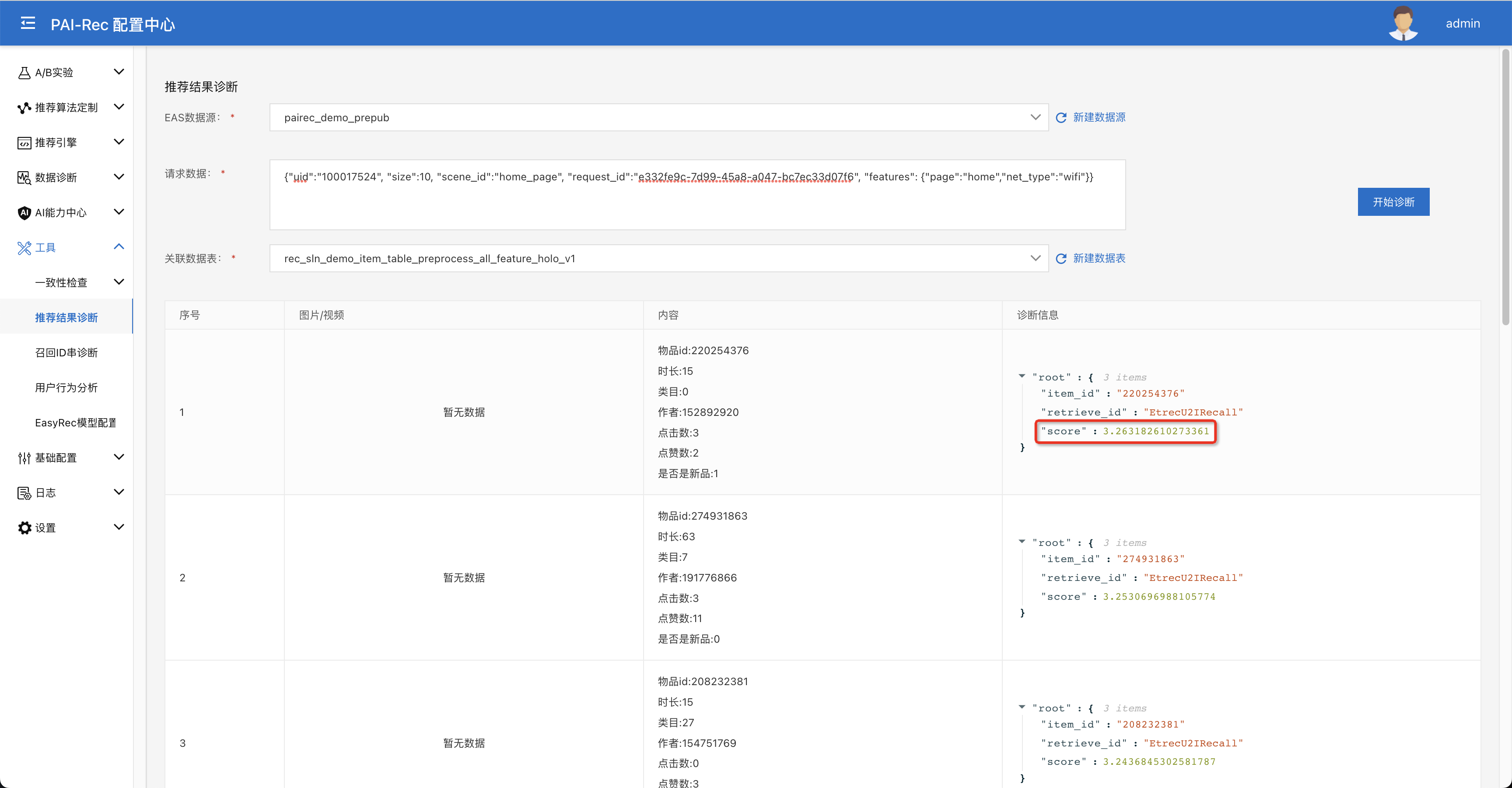
调试实验:跟在线服务章节中相似,我们进入工具 > 推荐结果诊断页面,用绑定的用户的uid重新给预发服务打一个请求,我们可以看到模型的打分符合预期,比原来提升了10倍
发布生产:预发调试完成后,我们同样可以通过克隆的方式将实验发布到生产环境
进入A/B实验 > 实验室管理 > 预发页面,点击克隆按钮,环境选择生产,是否克隆实验组选择是,则可以将预发环境的A/B实验配置克隆到生成环境
将生成环境的实验室/实验组/实验分别发布上线
进入工具 > 推荐结果诊断页面,调试生产环境的推荐接口的返回结果,查看生产环境配置是否生效
A/B指标报表配置与查看¶
上线完实验,同样重要的是如何查看指标报表,进行科学的实验对比,本小节基于示例数据和已上线的实验模型讲解如何配置和查看一个简单的离线指标报表。主要包括3部分, 指标数据源的接入, 指标的定义, 实验指标的可视化展示。如需要进一步使用实时报表等高级功能,请参见用户手册。
数据源接入:数据源包含两部分,数据来源表,以及数据结果表。数据来源表是指标计算的原始数据MaxCompute表,数据结果表是指标计算结果的Hologres表,A/B的指标报表系统会根据指标定义对数据来源表进行加工计算,将结果写入数据结果表中用于报表展示,详细表的定义和说明参见手册。基于示例数据我们可以进行如下配置
示例数据的行为表中包含exp_id(实验ID)字段,实验ID字段唯一标识了流量是属于哪个分层实验的,对于跟踪实验效果来说至关重要,在实际的业务场景中,exp_id字段一般是通过埋点推荐引擎的返回结果得到的。为了方便演示,我们可以参考附录B对示例数据中的exp_id字段的进行修订,使其与刚新建的实验匹配起来。
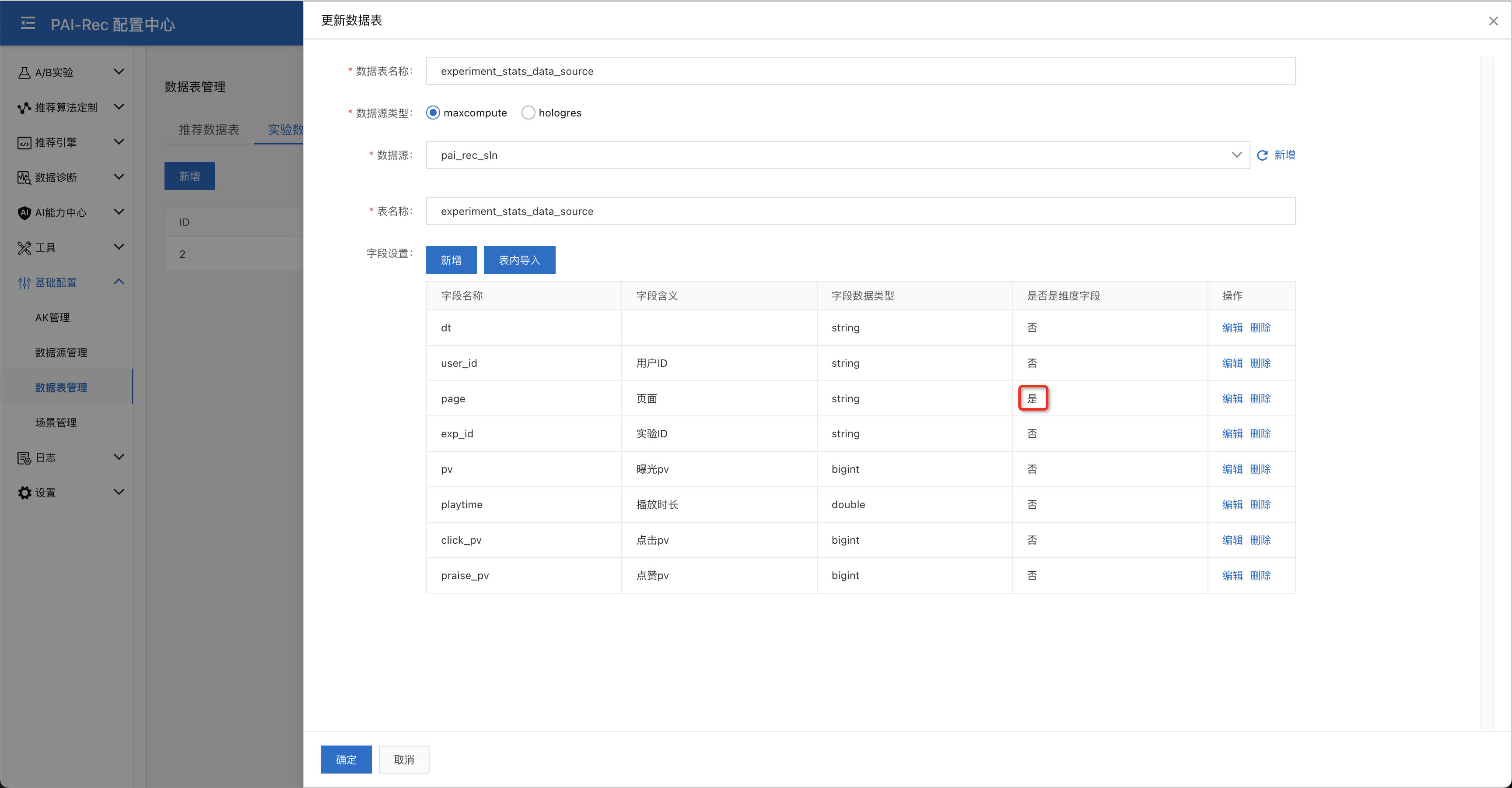
数据来源表:参考附录C中提供的MaxCompute SQL,在DataWorks > 数据开发中新建一个ODPS SQL节点新建一张名叫experiment_stats_data_source数据来源表,并提交。右键该节点选择在运维助手中定位,在运维助手中补7天数据。进入运维与实验操作台的基础配置 > 数据表管理 > 实验数据表新增这张数据来源表,可以通过表内导入来获取表的schema,中page字段需要设置为维度字段
数据结果表:参考附录D中提供的Hologres SQL,在DataWorks > 临时查询中新建一个Hologres SQL脚本新建名叫demo_ab_test_result的数据结果表。进入运维与实验操作台的基础配置 > 数据表管理 > 实验数据表新增一张数据结果表,同样可以通过表内导入来获取表的schema。
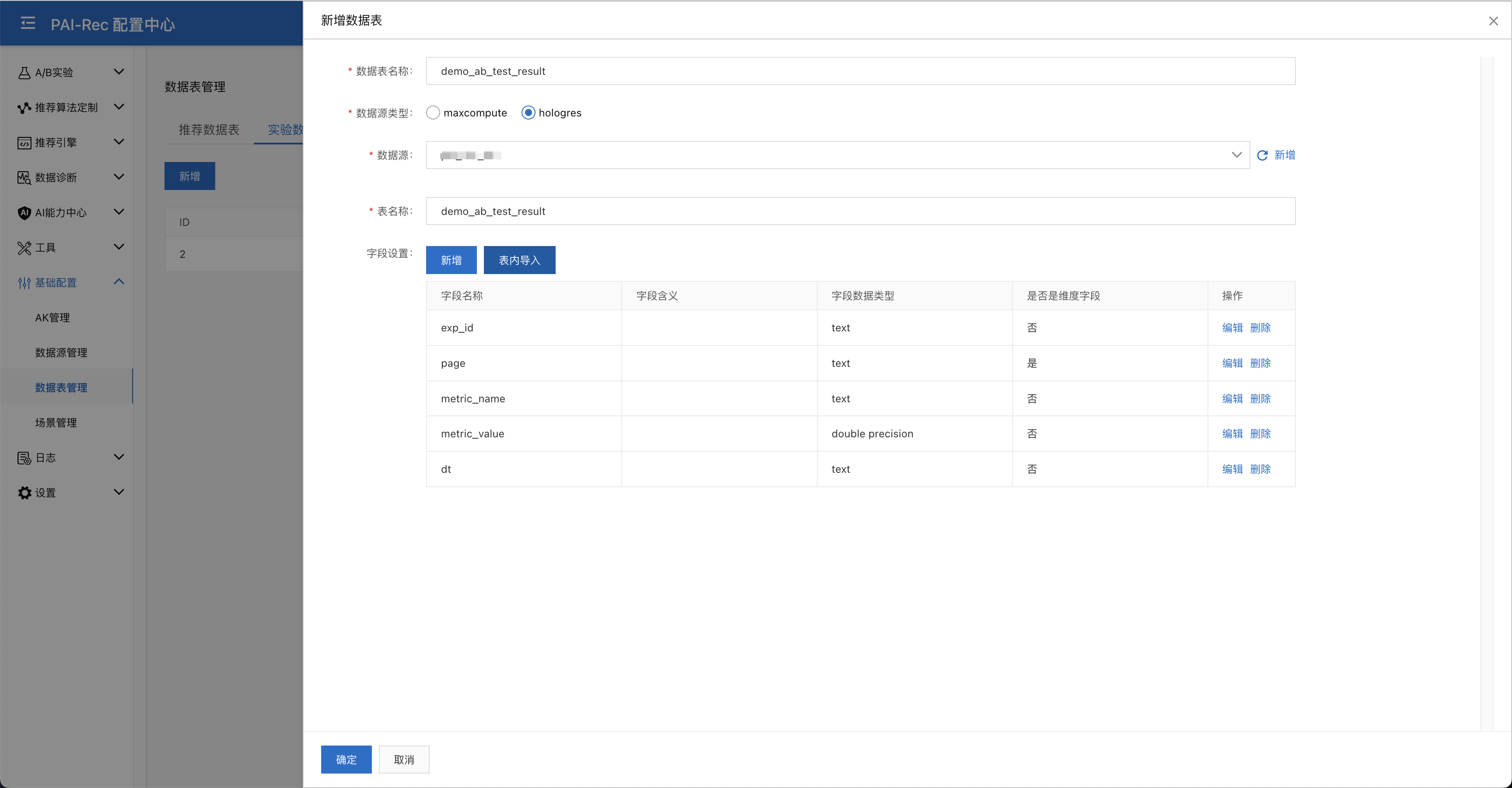
指标定义:
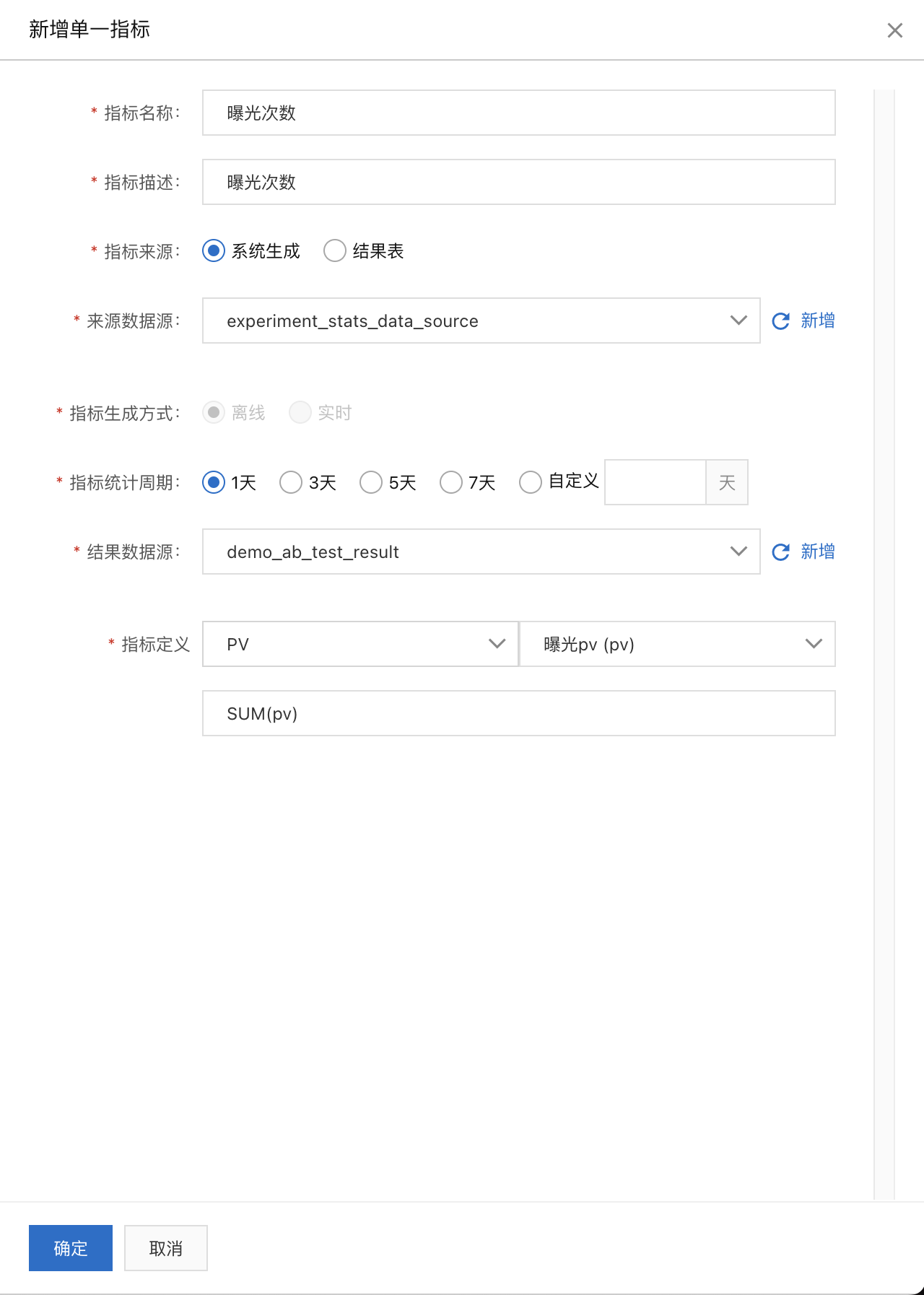
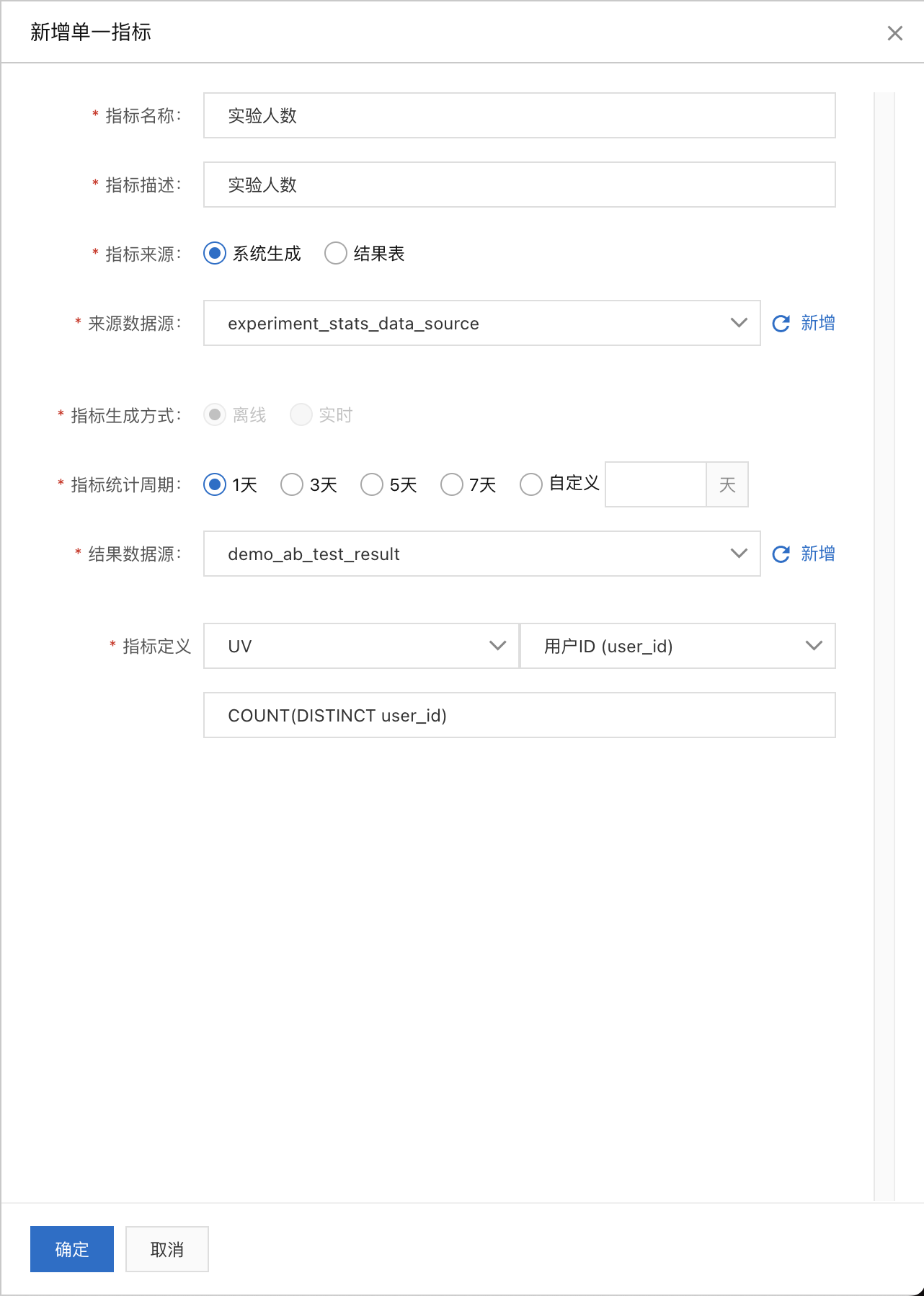
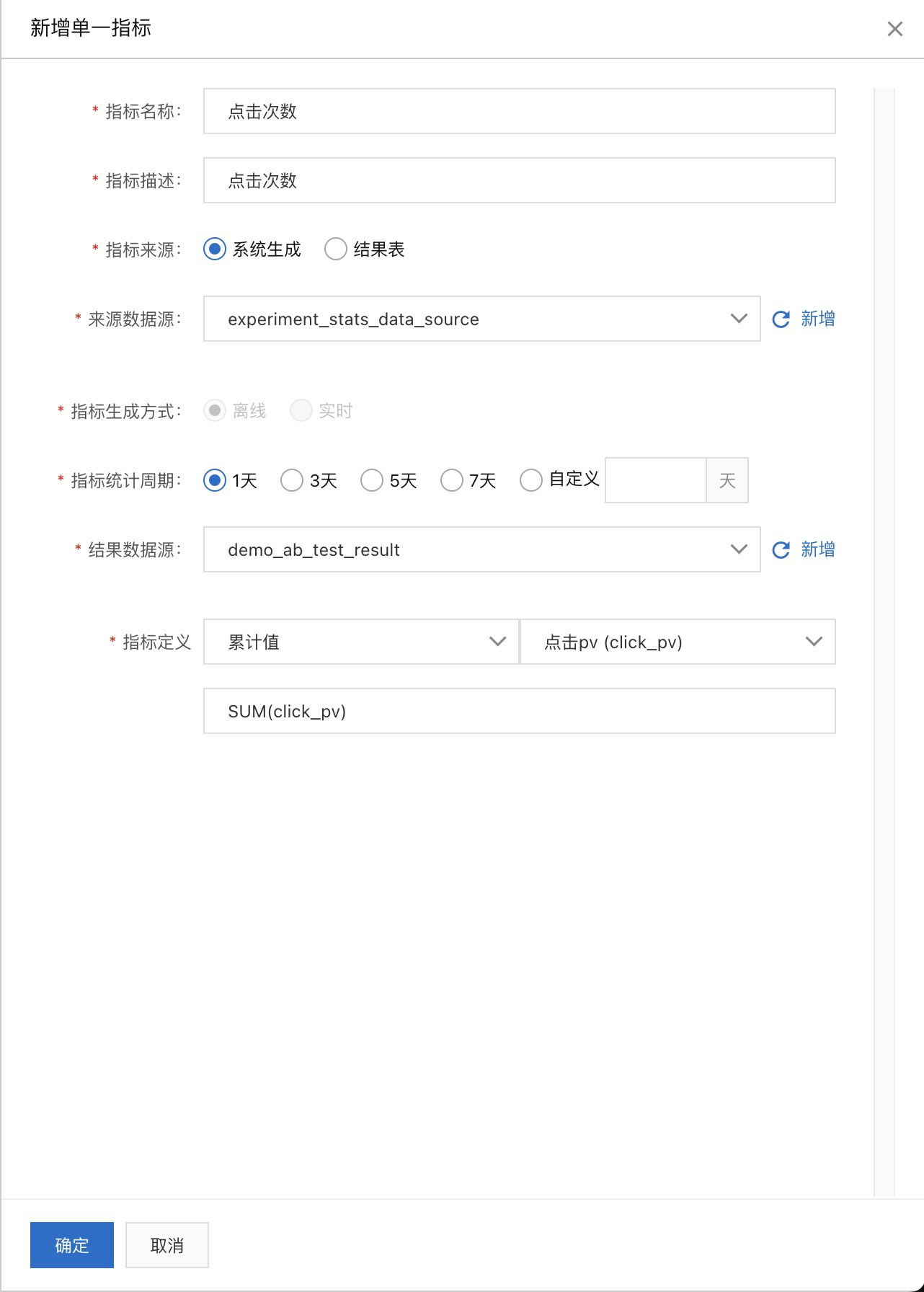
单一指标定义:进入A/B实验 > 指标配置页面新建几个单一指标“曝光次数”、“实验人数”、“点击次数”,可以点击指标诊断来观察指标是否配置正确
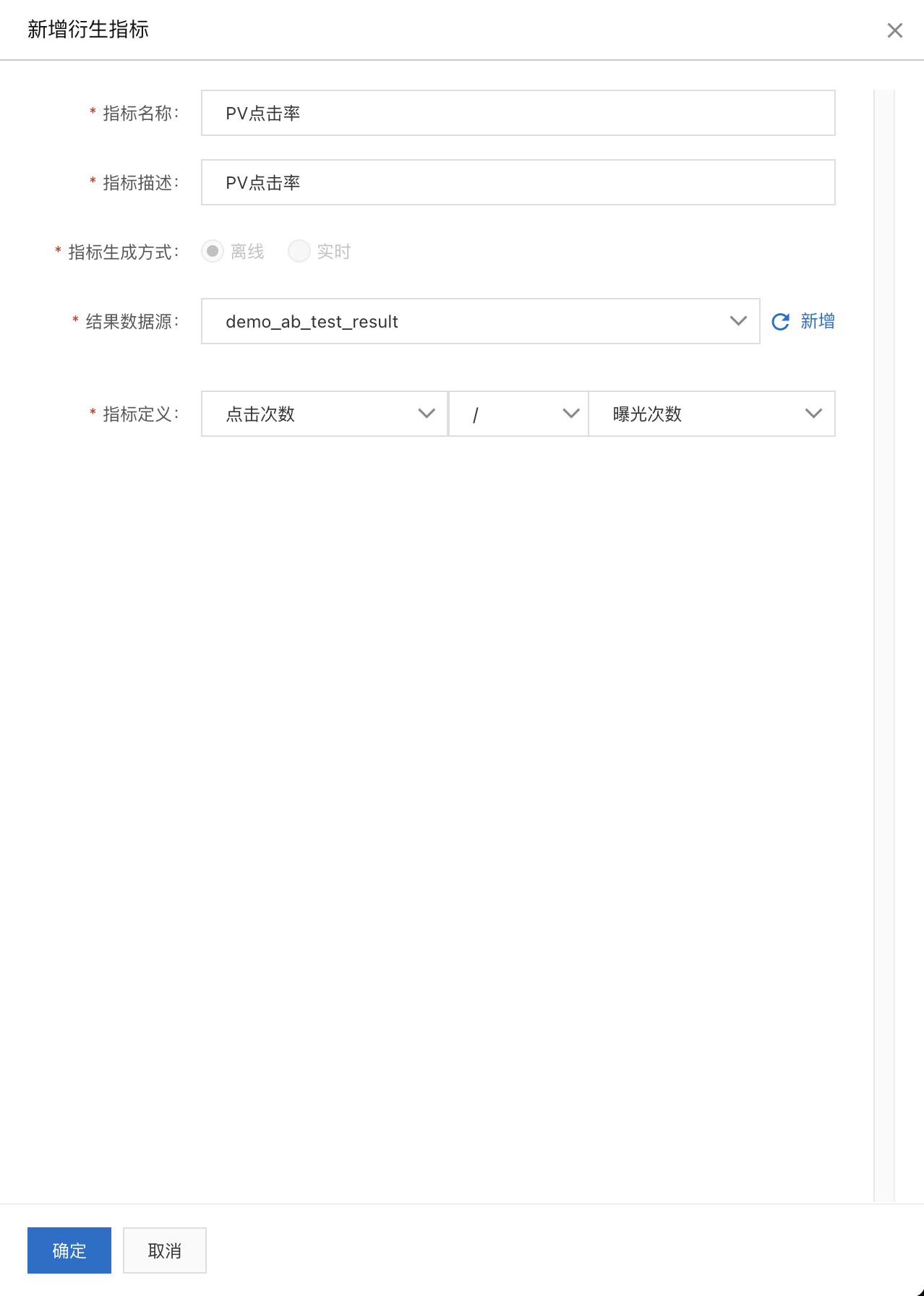
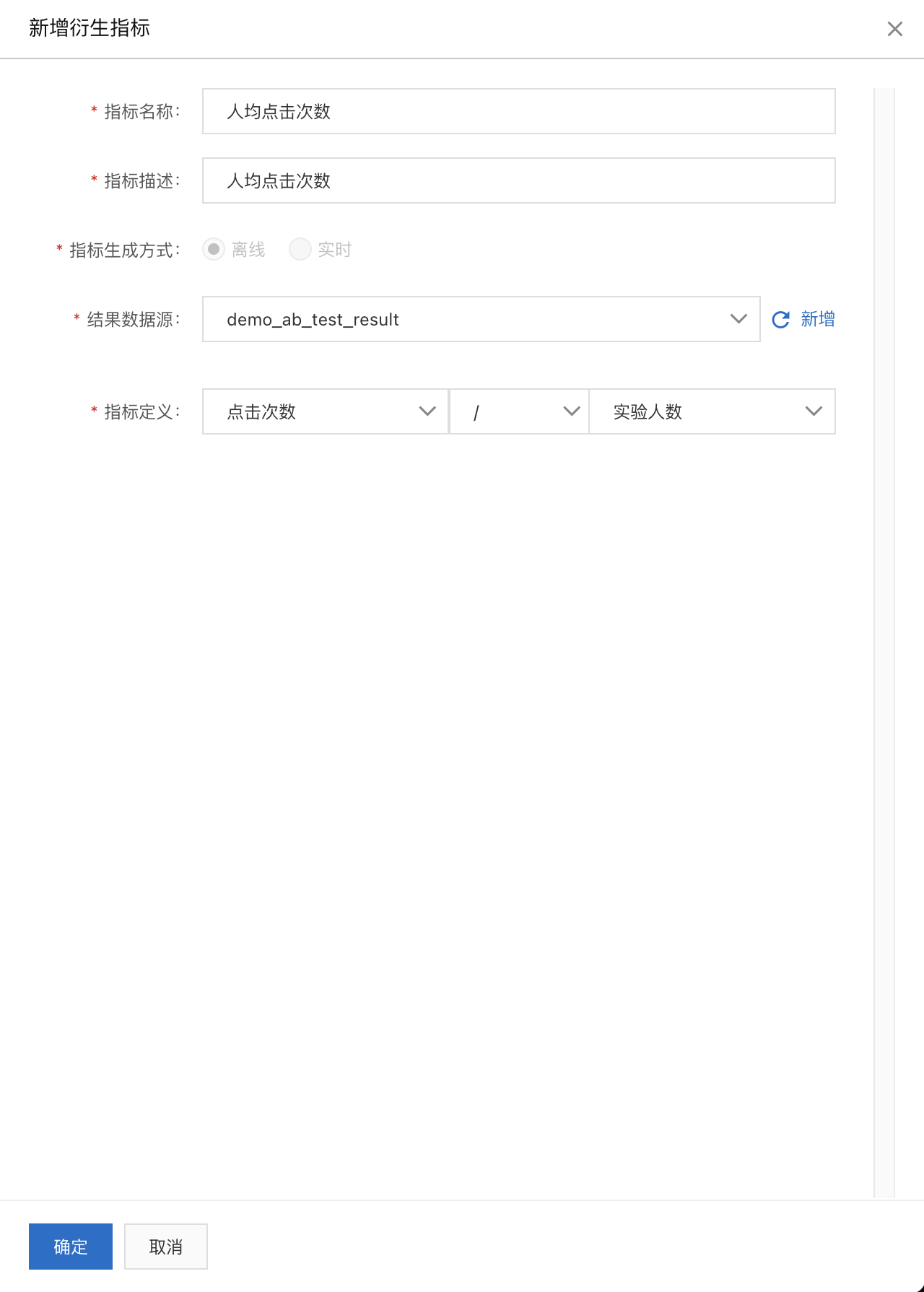
衍生指标定义:在A/B实验 > 指标配置页面再新建几个衍生指标“PV点击率”、“人均点击次数”
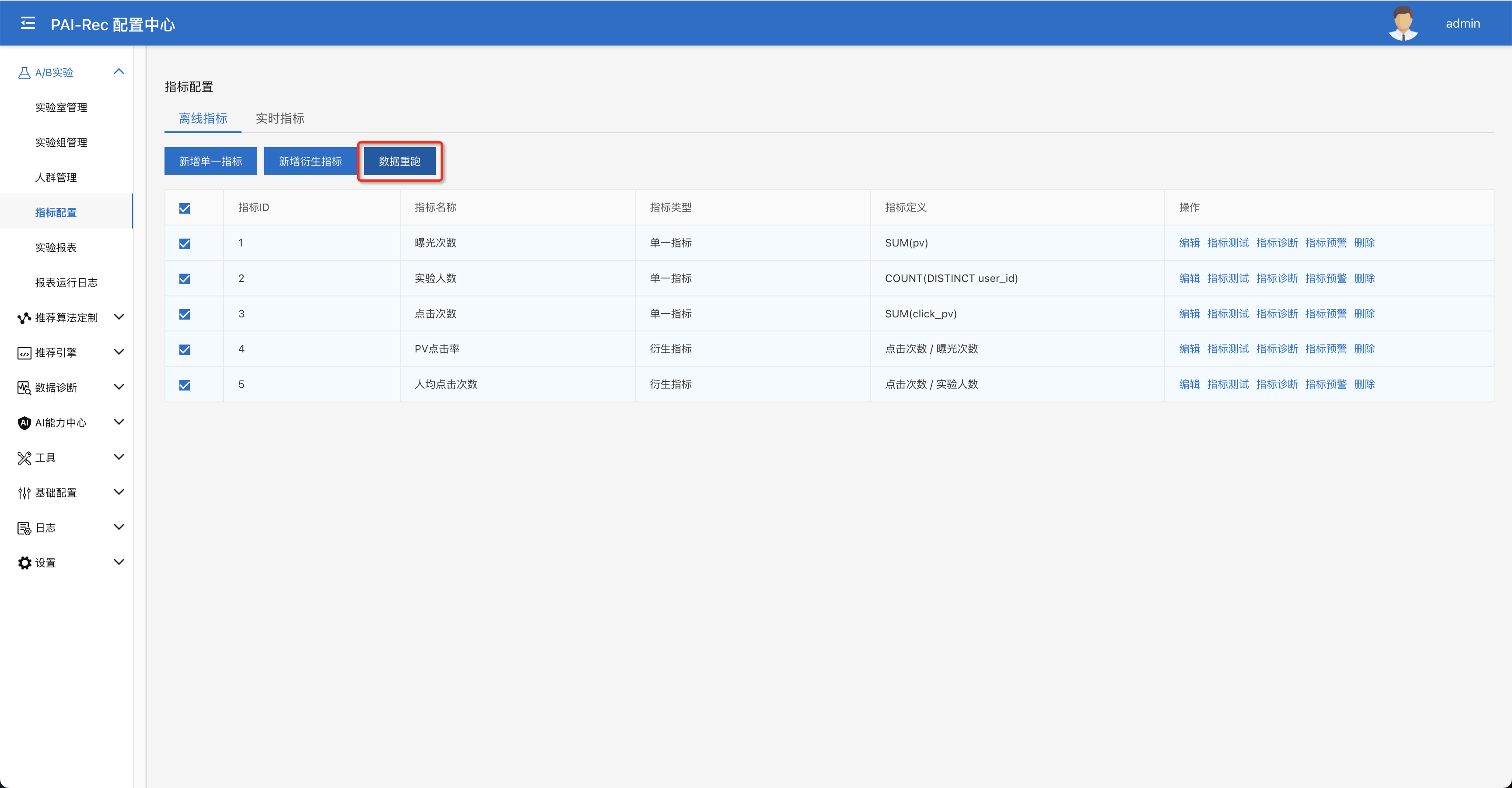
补数据:进入A/B实验 > 指标配置页面,选择刚新建个指标,点击数据重跑进行补数据,生成历史数据上的指标效果报表,在A/B实验 > 报表运行日志页面上可以看到任务的运行日志
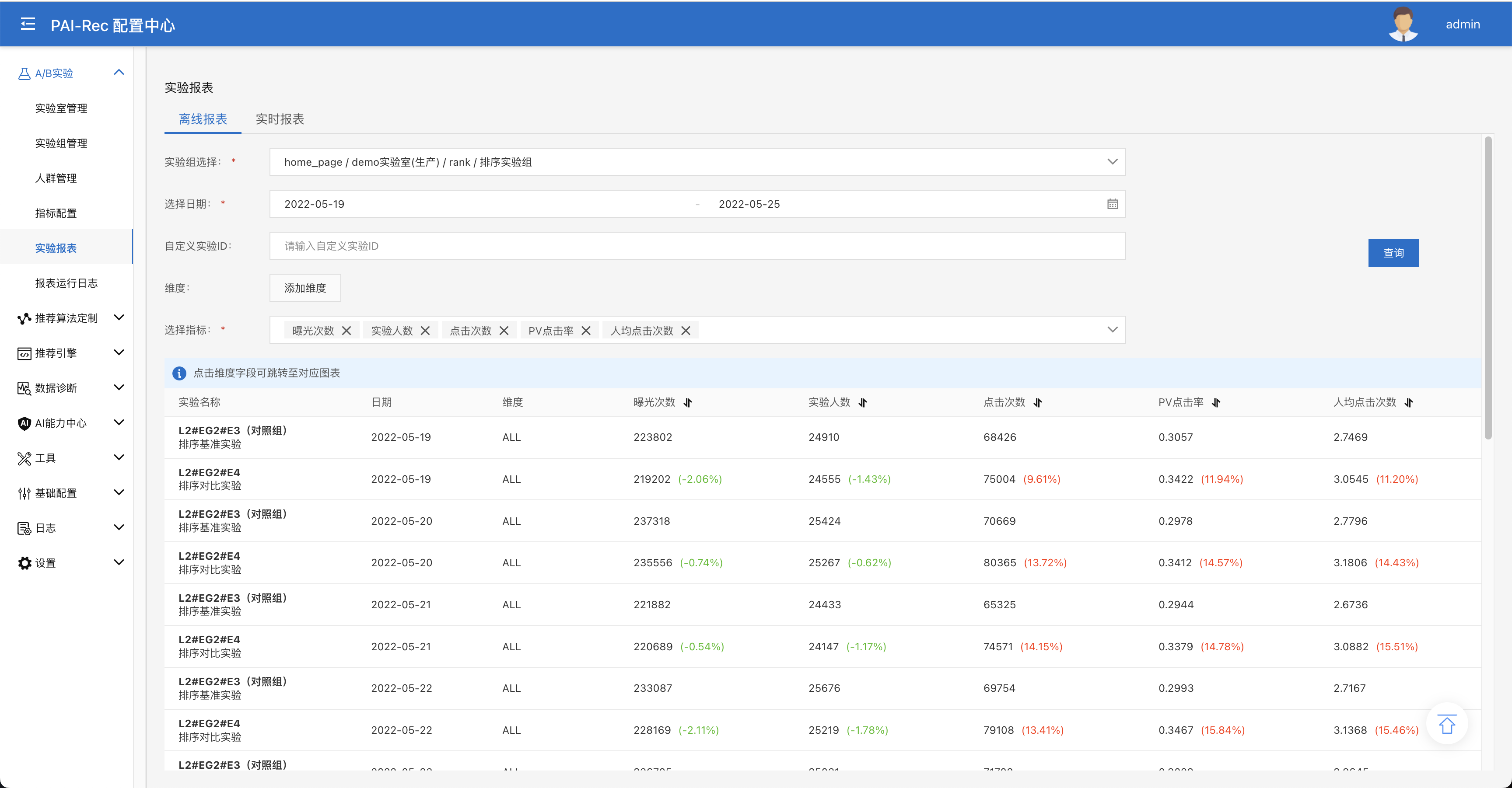
报表查看:进入A/B实验 > 指标报表页面,选择home_page/demo实验室(生产)/rank上的排序实验组,选择刚补数的周期,以及刚新建的指标,点击查询,可以看到这层上的实验报表
最佳实践¶
1.怎么配置UV购买转化率?¶
对于电商用户来说,我们需要计算uv购买转化率。而转化率是购买UV除曝光UV,我们可以如下配置:
购买UV:count(distinct if(gmv>0,user_id,NULL))
曝光UV:count(distinct user_id)
再配置一个衍生指标:购买UV / 曝光UV
2.通过配置小时行为表提升迭代效率¶
配置小时行为表可以每个小时计算实验桶的效果,让算法工程师当天看到实验上线后的效果。如果效果有问题,算法工程师可以快速定位问题并调整实验。这样能够大大提高实验效率。
3.如果要对比每个桶曝光item的数量怎么办?¶
我们可能担心新实验推荐了更多的热门商品,但是要怎么衡量呢?可以统计item_id + exp_id 作为key的统计表,然后配置曝光item数量、点击item数量、转化率等指标,这样就可以满足观察算法是否推荐了过多热门物品的需求。
附录¶
附录A:排序对比实验配置¶
{
"features.scene.name":"home_page",
"rankconf":{
"RankAlgoList":[
"home_page_dbmtl"
],
"RankScore": "10 * ${home_page_dbmtl_probs_is_click} + ${home_page_dbmtl_y_play_time} + ${home_page_dbmtl_probs_is_praise}",
"BatchCount": 500,
"Processor": "EasyRec"
}
}
附录B:示例实验数据修订¶
示例数据是随机生成构造的,因此我们要修订生成数据以匹配我们上线的实验(实际业务场景中数据是埋点自然产生的,则不需要这一步)
进入A/B实验 > 实验室管理 > 生产页面,获取到刚新建的demo实验室的ID,如实验室的ID为2,则exp_id的前缀为ER2
进入A/B实验 > 实验组管理页面,选择home_page - demo实验室(生产) - rank层下的排序实验组,点击更新按钮,获取到排序基准实验和排序对比实验的ID,如两个实验的ID为L2##EG2##E3 和 L2##EG2##E4,则完整的exp_id分别为ER2_L2##EG2##E3 和 ER2_L2##EG2##E4
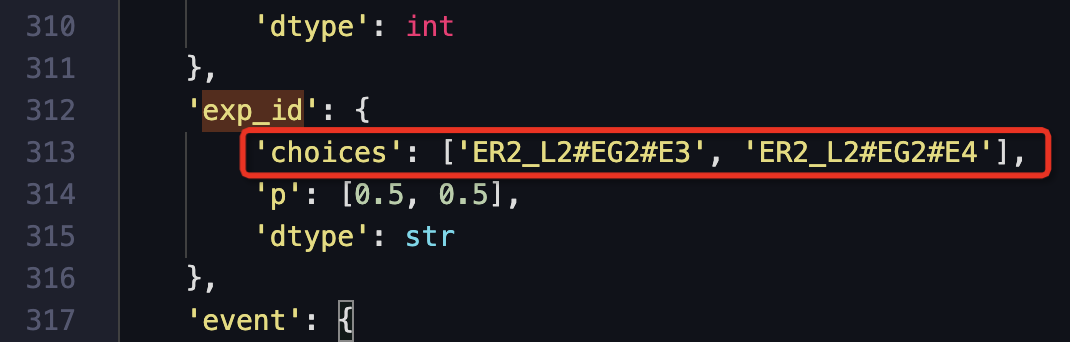
进入DataWorks数据开发页面编辑content_scene_data节点中的exp_id的choices为
['ER2_L2##EG2##E3','ER2_L2##EG2##E4'],多层的情况及详细的实验id的介绍可以参考[流量模型]([‘ER3_L2##EG2##E3’, ‘ER3_L2##EG2##E4’])文档
右键content_scene_data节点选择在运维中心中定位,重新给content_scene_data补7天数据
附录C:示例实验数据来源表MaxCompute SQL¶
CREATE TABLE IF NOT EXISTS experiment_stats_data_source
(
user_id STRING COMMENT '用户ID',
page STRING COMMENT '页面',
exp_id STRING COMMENT '实验ID',
pv BIGINT COMMENT '曝光pv',
playtime DOUBLE COMMENT '播放时长',
click_pv BIGINT COMMENT '点击pv',
praise_pv BIGINT COMMENT '点赞pv'
)
PARTITIONED BY (dt STRING)
;
INSERT OVERWRITE TABLE experiment_stats_data_source PARTITION(dt='${bdp.system.bizdate}')
SELECT user_id,
page,
exp_id,
sum(is_expr) AS pv,
round(sum(playtime), 2) AS playtime,
sum(is_click) AS click_pv,
sum(is_praise) AS praise_pv
FROM (
SELECT user_id,
item_id,
exp_id,
page,
sum(playtime) AS playtime,
max(if(event='expr', 1, 0)) AS is_expr,
max(if(event='click', 1, 0)) AS is_click,
max(if(event='praise', 1, 0)) AS is_praise
FROM rec_sln_demo_behavior_table
WHERE dS = '${bdp.system.bizdate}'
GROUP BY user_id, item_id, exp_id, page
)
GROUP BY user_id, exp_id, page;
附录D:示例实验数据结果表Hologres SQL¶
CREATE TABLE public.demo_ab_test_result (
exp_id text NOT NULL, -- 实验ID
page text NOT NULL, -- 维度字段
metric_name text NOT NULL,
metric_value double precision NOT NULL,
dt text NOT NULL
);
CALL set_table_property('public.demo_ab_test_result', 'orientation', 'column');
CALL set_table_property('public.demo_ab_test_result', 'clustering_key', 'metric_name,dt');
CALL set_table_property('public.demo_ab_test_result', 'time_to_live_in_seconds', '7776000');