A/B实验¶
实验室管理¶
实验室是一组流量的集合,可以是一个实验室,也可以创建多个实验室。
必须要有 base 实验室,流量会优先匹配非 base 实验室,当流量没有匹配到实验室时,会进入 base 实验室进行兜底。
新增¶
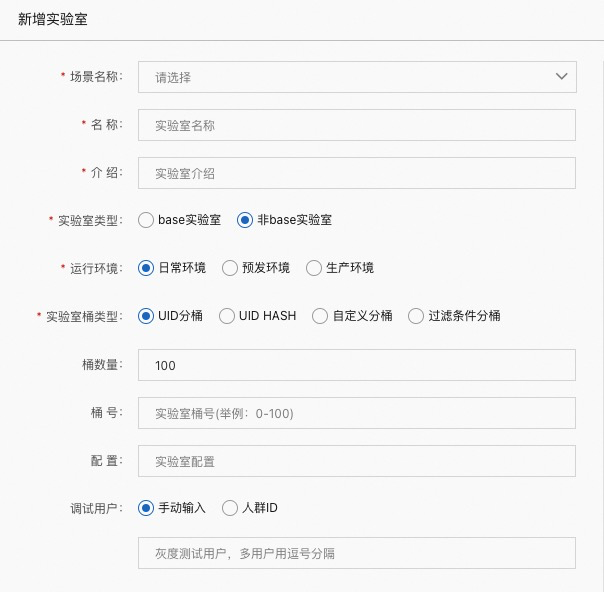
场景名称:实验室所属场景
名称:自定义名称
介绍:实验室的详细描述
实验室类型:
base 实验室:兜底实验室
非 base 实验室:优先匹配非 base 实验室
运行环境:对应引擎的运行环境,日常(daily), 预发(prepub),生产(product)
实验室桶类型:
UID分桶:根据 uid 的末尾数字分桶
UID HASH:根据 uid 的 hash 值分桶
过滤条件分桶:kv 表达式分桶,如
gender=man
桶数量:此实验室分得的桶数,总数为100
桶号:分得的桶的编号
配置:实验室自定义配置
调试用户:调试用户可以不经过匹配,直接进入此实验室
手动输入:可以输入多个,以逗号分隔
人群 ID:一组 uid 的集合,需要提前在【人群管理】中创建
输入并选择所需配置,点击【确认】按钮即可。
上线/下线¶
将实验室状态更改为”上线”/”下线”,此时引擎的流量可以进入此实验室
层管理¶
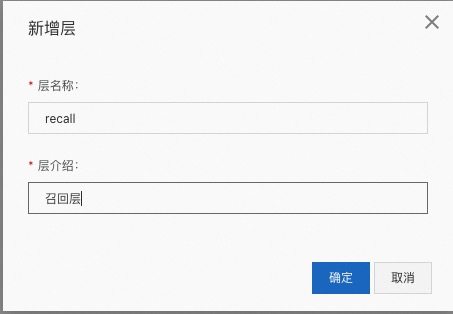
进入【层管理】来管理分层信息。可以添加单层,也可以多层。多层之间流量是正交的,可以有效复用流量。
比如要添加召回层,如下:
克隆¶
克隆功能可以将当前实验室克隆到其他环境。
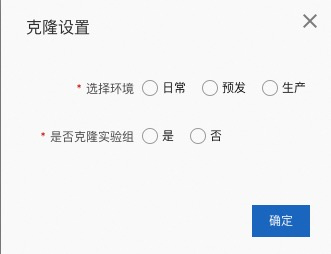
选择环境:要克隆到的目的环境
是否克隆试验组:是否将属于此实验室的试验组也克隆到目的环境
实验组管理¶
通过【实验组管理】可以创建实验。实验组是一个逻辑概念,里面包含具体的实验,比如基准实验和对比实验,对比实验可以添加多个。
新增¶
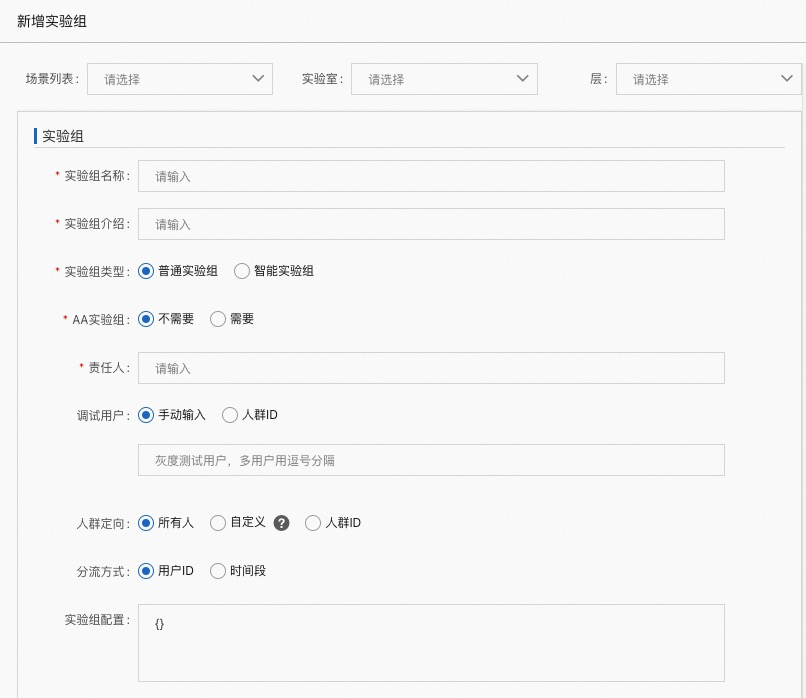
场景列表:此实验组所属场景
实验室:此实验组所属实验室
层:此实验组所属层
实验组名称:自定义名称
实验组介绍:实验组详细描述
实验组类型:
普通实验组:
智能实验组:上线的所有的实验均分流量
AA 实验组:
不需要:
需要:会创建一个影子实验
责任人:创建者
调试用户:调试用户可以跳过分桶规则,直接进入此实验室
手动输入:可以输入多个,以逗号分隔
人群 ID:一组 uid 的集合,需要提前在【人群管理】中创建
人群定向:
所有人:相当于不设置匹配规则
自定义:自定义表达式
人群 ID:一组 uid 的集合,需要提前在【人群管理】中创建
分流方式:
用户 ID:按照用户 ID 进行分桶
时间段:按照时间段进行分桶
实验组配置:
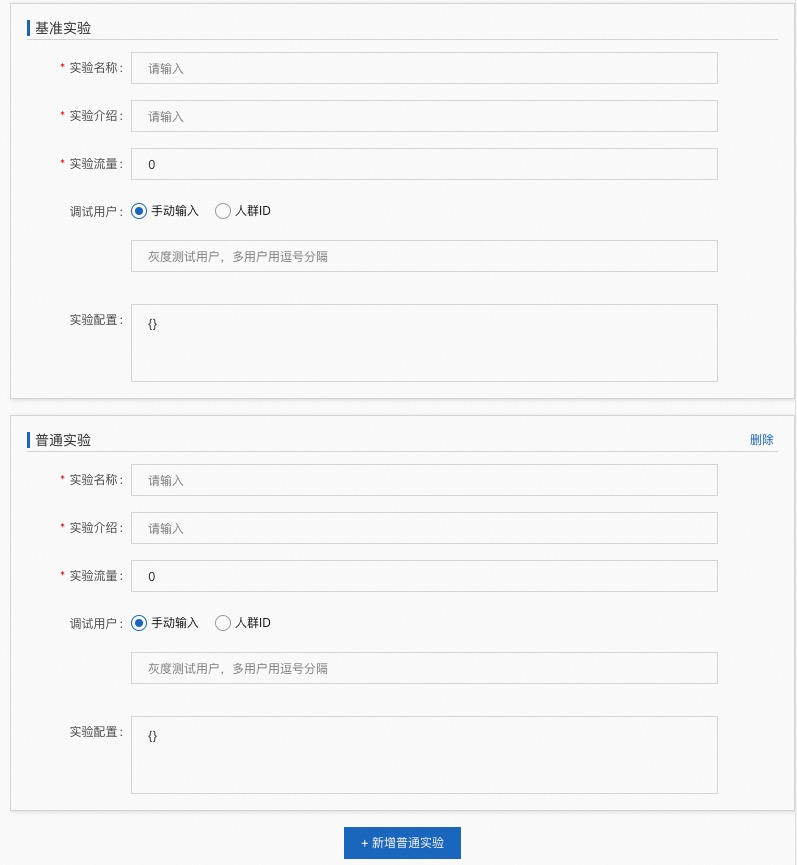
基准实验¶
实验名称:自定义名称
实验介绍:关于此实验的详细描述
实验流量:此实验所占流量,总数为 100
调试用户:含义同实验组中相同
实验配置:若引擎命中此实验,会优先加载并使用此配置,支持召回、过滤、粗排、精排等的配置
普通实验¶
参数意义同上。
克隆¶
将此实验组克隆到目的场景/实验室/层下
人群管理¶
人群管理提供的是一个用户集合的功能,类似于用户白名单功能,可以在【实验室管理】、【实验组管理】中选择使用
新增¶
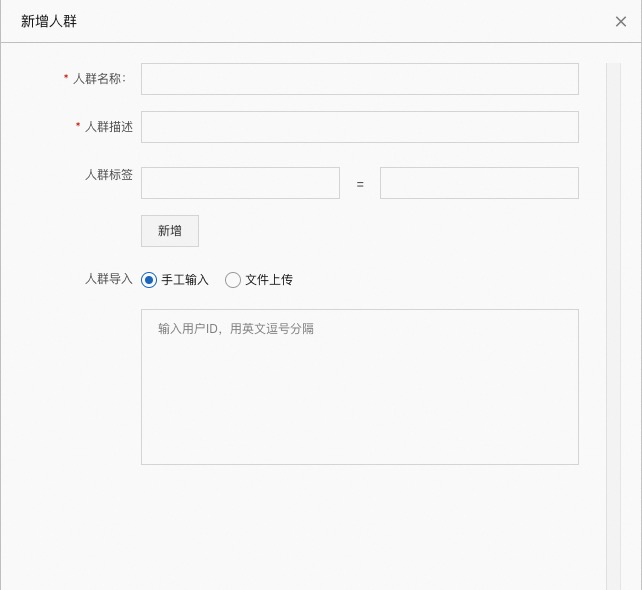
人群名称:自定义名称
人群描述:详细描述
人群标签:可以自定义人群标签
人群导入:可以手动输入,可以通过文件上传
人群管理¶
【人群管理】可以对创建的某个条目中的人群 ID 进行增加、删除、查看,可以管理多个批次
指标配置¶
【指标配置】分为【离线指标】和【实时指标】,两者的配置基本一样。此处以【离线指标】为例
新增单一指标¶
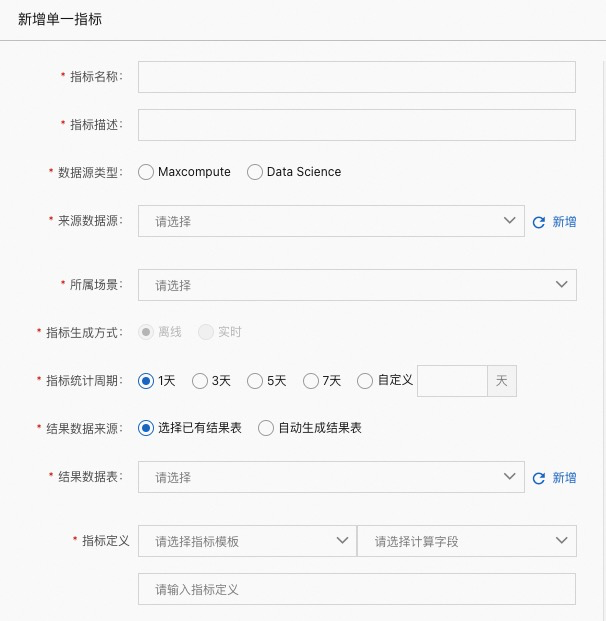
指标名称:指标的名称
指标描述:指标的详细描述
数据源类型:数据源的类型
来源数据源:数据的源表
所属场景:指标所属场景
指标统计周期:T-N 的计算方式( T 为 today)
结果数据来源:
选择已有结果表:可以选择已经存在的结果表,并将结果写入到此表
自动生成结果表:需要选择数据源,会自动在所选数据源中创建结果表并写入
指标定义:指标的定义,内置了一些模版,若不满足,也可直接输入,如:sum(clilck)
新增衍生指标¶
点击【新增衍生指标】,弹出如下配置界面:
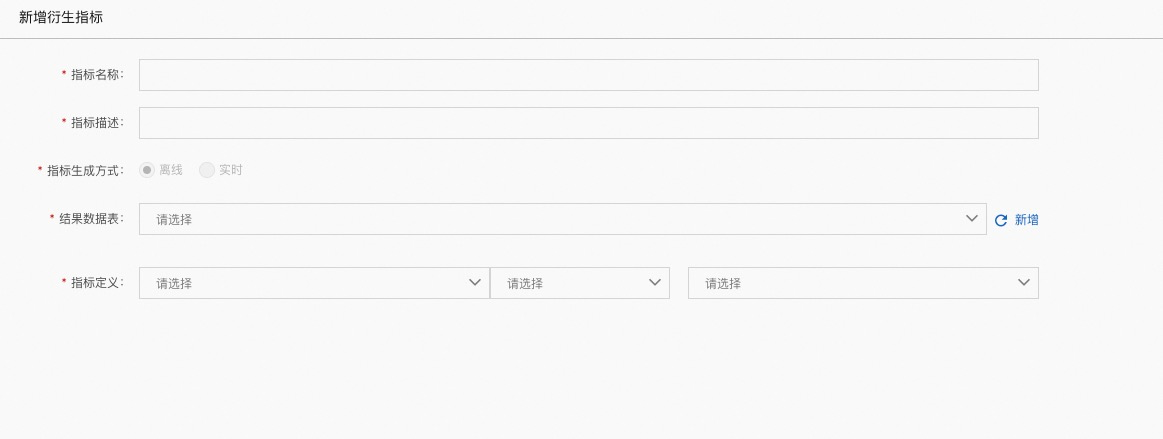
指标名称:自定义名称
指标描述:指标的详细描述
结果数据表:要写入的数据表
指标定义:两个原子指标的加减乘除
数据重跑¶
指标配置好之后,默认是每天早上 6 点运行,如果运行失败了,或者上游数据没有产出,导致结果为空,可以使用【数据重跑】
选择要重跑的指标,点击【数据重跑】
选择要重跑的日期即可。
重跑的任务状态可以到【报表运行日志】进行查看。
指标测试¶
指标诊断¶
此功能主要是检测数据源表和数据结果表的格式
数据源表格式如下:
字段名称 |
字段含义 |
是否必填 |
说明 |
|---|---|---|---|
user_id |
用户 id |
是 |
用户标识,应和引擎中的 user 的业务意义一致 |
exp_id |
实验 id |
是 |
引擎返回的实验 id,通过埋点回流 |
维度字段 |
维度字段,如 os,sex |
否 |
可以根据维度字段过滤对应的指标,如只想查看 Android 系统的点击率,可将所属字段设置为维度字段 |
计算字段 |
计算字段,如 show_count,click_count… |
是 |
要参与计算的字段,如曝光数,点击数,观看市场等 |
dt |
日期分区 |
是 |
格式 yyyyMMdd |
hh |
小时分区 |
离线指标否/实时指标是 |
24 小时制,00-23 |
数据结果表
字段名称 |
字段含义 |
是否必填 |
说明 |
|---|---|---|---|
exp_id |
实验 id |
是 |
引擎返回的实验 id,通过埋点回流 |
维度字段 |
维度字段,如 os,sex |
否 |
某个指标的数据源表和数据结果表的维度字段应该是相同的 |
metric_name |
创建的指标的指标名称 |
是 |
指标名称 |
metric_value |
指标的值 |
是 |
float64 值 |
dt |
日期字段 |
是 |
格式 yyyyMMdd |
hh |
小时字段 |
离线指标否/实时指标是 |
24 小时制,00-23 |
指标预警¶
指标预警功能可以设置一个阈值,当指标的波动大于此阈值时,会通过指定的方式发送告警信息,目前只支持钉钉渠道。
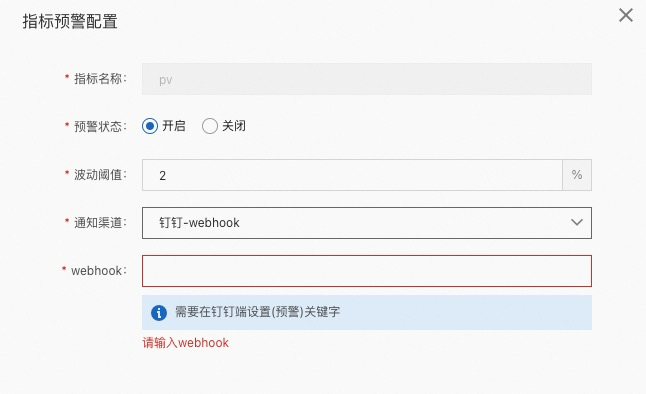
webhook:在钉钉群内创建机器人时,可以得到一个 webhook,注意,要使用
自定义关键词方式并设置预警这个关键字
实验报表¶
实验报表分为离线报表和实时报表,分别对应离线指标和实时指标,报表的查看可以通过通过级联选择,选择到某个实验组,来查看此实验组各个实验的指标值以及与 base 实验的差异。
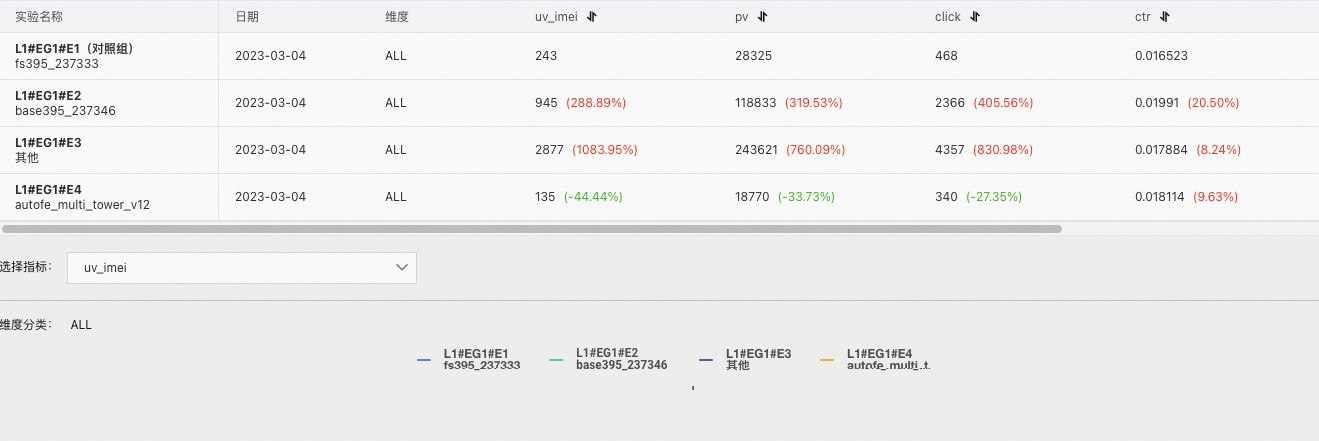
这里还可以设置维度,比如根据操作系统来区分实验效果。不设置维度值,会把此维度的所有维度值结果展示出来。
报表运行日志¶
报表运行日志,展示的是离线指标的运行日志,其中 Message 字段展示的是任务运行的详细信息,里面包含指标计算的 SQL 等信息。
诊断任务¶
目前指标诊断分为 4 种诊断任务,分别为:
指标排序:在用户粒度统计实验指标并排序, 保留前N个结果
指标分布:统计用户粒度的实验指标分布
维度分析:对维度字段分布的统计, 仅支持离散取值的字段
多桶用户:串桶用户的实验链路和串桶用户数量
下面以指标排序为例讲解诊断步骤:
新建任务¶

任务类型:选择指标排序
任务名称:自定义名称
数据表类型:数据表所在的数据源类型
数据表:待分析的数据表,需提前在【数据表管理】中注册
指标选择:待分析的指标
排序 ID 字段:排序的ID字段, user_id 或者 item_id
topN设置:记录统计指标排名的TOP个数
任务运行¶
创建完成之后,勾选已有的任务,点击【数据重跑】,选择补数据周期,点击确认即可
任务日志¶
在【任务日志】页面可以看到数据诊断任务的运行日志
诊断报告¶
在【诊断任务/任务管理】页面,点击相应任务的【报告】,可以查看具体任务的诊断报告