快速开始¶
2. 安装步骤¶
- pip install cython
- pip install http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/release/easy_vision-1.0.7-py2.py3-none-any.whl
- 验证:
import easy_vision
如下安装第三方库下载缓慢,可以采取如下方式更改pip源加速
新建 ~/.config/pip/pip.conf 文件
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
3. 使用步骤¶
3.1 数据准备¶
下载pascal数据集(在当前目录):
osscmd downloadallobject oss://pai-vision-data-hz/data/voc0712_tfrecord/ data/voc0712_tfrecord --host=oss-cn-zhangjiakou.aliyuncs.com
# or use oss util, 需要在配置文件中设置host为oss-cn-zhangjiakou.aliyuncs.com
ossutil cp -r oss://pai-vision-data-hz/data/voc0712_tfrecord/ data/voc0712_tfrecord
下载resnet50预训练模型(在当前目录):
mkdir -p pretrained_models/
ossutil cp -r oss://pai-vision-data-hz/pretrained_models/resnet_v1d_50/ pretrained_models/resnet_v1d_50
3.2 启动训练任务¶
普通配置模式
import easy_vision
easy_vision.train_and_evaluate(easy_vision.RFCN_SAMPLE_CONFIG)
参数配置模式
import easy_vision
param_config = """
--model_type RFCN
--backbone resnet_v1d_50
--num_classes 20
--model_dir experiments/pascal_voc/resnet50_rfcn_model
--train_data data/voc0712_tfrecord/voc0712_part_*.tfrecord
--test_data data/voc0712_tfrecord/VOC2007_test.tfrecord
--num_test_example 2
--train_batch_size 32
--test_batch_size 1
--image_min_sizes 600
--image_max_sizes 1024
--lr_type exponential_decay
--initial_learning_rate 0.001
--decay_epochs 20
--staircase true"""
easy_vision.train_and_evaluate_with_param_config(param_config)
PS模式
需要在具有至少两张GPU卡的机器上才能运行,一共需要启动3个子进程,分别是ps(parameter server), master(训练过程,负责写summary,保存checkpoint, 定期evaluation),worker(训练过程),脚本如下:
#-*- encoding:utf-8 -*-
import multiprocessing
import sys
import os
import easy_vision
import json
import logging
import subprocess
import time
# train config under distributed settings
config=easy_vision.RFCN_DISTRIBUTE_SAMPLE_CONFIG
print('config path: %s' % config)
# cluster spec
TF_CONFIG={'cluster':{
'ps': ['localhost:12921'],
'master': ['localhost:12922'],
'worker': ['localhost:12923']
}
}
def job(task, gpu):
task_name = task['type']
# redirect python log and tf log to log_file_name
# [logs/master.log, logs/worker.log, logs/ps.log]
log_file_name = "logs/%s.log" % task_name
TF_CONFIG['task'] = task
os.environ['TF_CONFIG'] = json.dumps(TF_CONFIG)
os.environ['CUDA_VISIBLE_DEVICES'] = gpu
train_cmd = 'python -m easy_vision.python.train_eval --pipeline_config_path %s' % config
logging.info('%s > %s 2>&1 ' % (train_cmd, log_file_name))
with open(log_file_name, 'w') as lfile:
return subprocess.Popen(train_cmd.split(' '), stdout= lfile, stderr=subprocess.STDOUT)
if __name__ == '__main__':
procs = {}
# start ps job on cpu
task = {'type':'ps', 'index':0}
procs['ps'] = job(task, '')
# start master job on gpu 0
task = {'type':'master', 'index':0}
procs['master'] = job(task, '0')
# start worker job on gpu 1
task = {'type':'worker', 'index':0}
procs['worker'] = job(task, '1')
num_worker = 2
for k, proc in procs.items():
logging.info('%s pid: %d' %(k, proc.pid))
task_failed = None
task_finish_cnt = 0
task_has_finished = {k:False for k in procs.keys()}
while True:
for k, proc in procs.items():
if proc.poll() is None:
if task_failed is not None:
logging.error('task %s failed, %s quit' % (task_failed, k))
proc.terminate()
if k != 'ps':
task_has_finished[k] = True
task_finish_cnt += 1
logging.info('task_finish_cnt %d' % task_finish_cnt)
else:
if not task_has_finished[k]:
#process quit by itself
if k != 'ps':
task_finish_cnt += 1
task_has_finished[k] = True
logging.info('task_finish_cnt %d' % task_finish_cnt)
if proc.returncode != 0:
logging.error('%s failed' %k)
task_failed = k
else:
logging.info('%s run successfuly' % k)
if task_finish_cnt >= num_worker:
break
time.sleep(1)
3.3 使用tensorboard观察训练过程¶
在模型目录下面可以看到保存的模型的checkpoint和event file,通过tensorboard可以查看loss, mAP等相关信息
tensorboard --port 6006 --logdir ${model_dir} [ --host 0.0.0.0 ]
- 训练Loss
如下图所示,loss是总的loss, loss/loss/rcnn_cls是分类loss, loss/loss/rcnn_reg是回归的loss,loss/loss/rpn_cls是RPN(RegionProposalNetwork)的分类loss,loss/loss/rpn_reg是RPN的回归loss。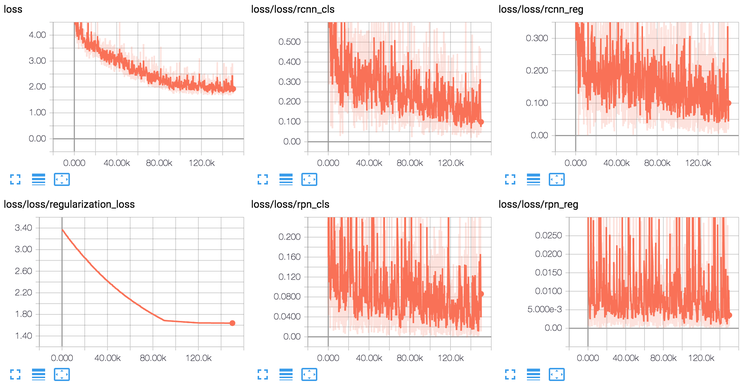
- 测试mAP
如下图所示,这里使用了两个常用物体检测的metric:PascalBoxes07和PascalBoxes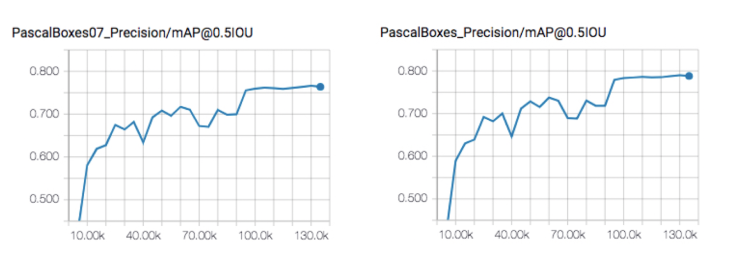
3.4 评估和预测¶
训练完成之后可以在其它数据集上测试,得到每张图的检测结果
import easy_vision
detect_results = easy_vision.predict(easy_vision.RFCN_SAMPLE_CONFIG)
也可以在训练完以后再次评估,评估的结果
import easy_vision
eval_metrics = easy_vision.evaluate(easy_vision.RFCN_SAMPLE_CONFIG)
3.5 导出模型¶
EasyVision可以方便地将模型导出成savedmodel格式,方便后续使用python、c++等语言进行预测使用
import easy_vision
easy_vision.export(export_dir, easy_vision.RFCN_SAMPLE_CONFIG, checkpoint_path)
导出程序会在export_dir下以当前unix时间戳创建模型目录,把checkpoint导出成savedmodel存放在目录下。
3.6 模型预测¶
我们提供了savedmodel的python版本的预测器,下面以检测模型为例,其余的如分类、分割、OCR等预测器详见模型预测文档
import easy_vision
detector = ev.Detector(saved_model_path)
image = np.zeros([640, 480, 3], dtype=np.float32)
output_dict = detector.predict([image])
预测结果以List of Json形式输出,List的Length与输入图像的张数相等,一下为各模型Json结果的示例与说明,Json结果样例如下:
{
"detection_boxes": [[243.5308074951172, 197.69570922851562, 385.59625244140625, 247.7247772216797], [292.1929931640625, 114.28043365478516, 571.2748413085938, 165.09771728515625]],
"detection_scores": [0.9942291975021362, 0.9940272569656372],
"detection_classes": [1, 1],
"detection_classe_names": ["text", "text"]
}
3.7 SavedModel评估¶
评估已导出的savedmodel,metric会打印在控制台中,predictor_eval_config的样例配置参见sample_config
from easy_vision.python.main import predictor_evaluate
predictor_evaluate(predictor_eval_config)