端到端文字识别¶
1 简介¶
传统的OCR算法中一般将文字检测和文字识别两个步骤相分离,作为两个任务分开进行训练优化,两者间相互耦合,需要大量的中间结果处理逻辑,整体算法的精度和速度缺乏很好的保障。为此我们检测+识别End-to-End的OCR算法,使得文字的检测和识别能级联起来形成一个End-to-End OCR算法,极大地简化了OCR算法训练和部署的难度识别精度提升了近2个百分点,识别速度则提升了1.7倍。端到端的文字识别模型相比于传统的检测和识别算法有较大优势,主要算法框架如下图所示。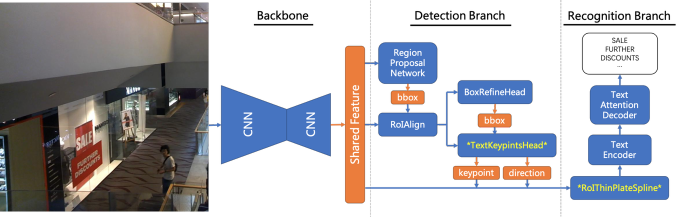
2 使用示例¶
下面我们以使用小票数据集,训练TextEnd2End模型为例,介绍如何训练一个端到端的文字识别模型
2.1 数据准备¶
小票数据我们提供了转换好的tfrecord, 下载小票数据到 data 文件夹下
ossutil cp -r oss://pai-vision-data-hz/data/recipt_text/end2end_tfrecords/ data/recipt_text/end2end_tfrecords/
下载我们提供了以中英文合成数据预训练的TextEnd2End模型预训练模型到pretrained_models文件夹下
ossutil cp -r oss://pai-vision-data-hz/pretrained_models/general_text_end2end_krcnn_attn_resnet50 pretrained_models/general_text_end2end_krcnn_attn_resnet50
2.2 模型训练¶
2.2.1 文件配置形式¶
运行如下python代码即可启动文件配置形式的训练评估流程,样例配置文件参见sample_config,配置文件参数说明参见proto文档。如果你使用了自定义的配置文件,把easy_vision.TEXT_END2END_SAMPLE_CONFIG_RECIPT 替换为你的配置文件路径即可。
import easy_vision
easy_vision.train_and_evaluate(easy_vision.TEXT_END2END_SAMPLE_CONFIG_RECIPT)
2.2.2 参数配置训练¶
运行如下python代码即可启动参数配置形式的训练评估流程
import easy_vision
param_config = """
--model_type TextEnd2End
--backbone resnet_v1_50
--num_classes 1
--use_pretrained_model true
--train_batch_size 1
--test_batch_size 1
--image_min_sizes 960
--image_max_sizes 1440
--initial_learning_rate 0.0001
--optimizer adam
--lr_type exponential_decay
--decay_epochs 40
--decay_factor 0.5
--num_epochs 10
--staircase true
--predict_text_direction true
--text_direction_trainable true
--text_direction_type smart_unified
--feature_gather_type fixed_height_pyramid
--train_data data/recipt_text/end2end_tfrecords/train_*.tfrecord
--test_data data/recipt_text/end2end_tfrecords/test.tfrecord
--model_dir experiments/recipt_text/text_end2end_krcnn_resnet50_attn"""
easy_vision.train_and_evaluate_with_param_config(param_config)
param_config 包含若干模型配置参数,格式遵循python argparser格式,各参数具体说明如下,所有字符串均不需要加引号
| 参数名称 | 参数描述 | 参数值格式 | 默认值 |
|---|---|---|---|
| model_type | 训练模型类型 | 字符串,可选范围 TextEnd2End |
无,必选字段 |
| backbone | 端到端文字识别模型使用的backbone | 字符串格式,可取值范围: resnet_v1_50 resnet_v1_101 |
无,必选参数 |
| weight_decay | l2 regularization的大小 | 浮点 | 1e-4 |
| num_classes | 检测类别数目,默认从数据集中分析得到 | 21 | -1 |
| anchor_scales | anchor框的大小,和resize后的输入图片在一个尺度。 设置大小时参考输入图片resize后的大小。 该参数只目前只支持填写一个值,表示分辨率最高layer的anchor大小,一共有5个layer,后面每个layer上每个anchor大小为前一layer的2倍, 例如 32, 64, 128, 256, 512 |
浮点列表 eg. 单一尺度 32 |
24 |
| anchor_ratios | anchor宽高比 | 浮点列表 | 0.2 0.5 1 2 5 |
| predict_text_direction | 是否预测文字行朝向 | 布尔 | false |
| text_direction_trainable | 是否训练文字行朝向预测 | 布尔 | false |
| text_direction_type | normal: 贪婪预测文字行方向 unified: 预测时将所有文字行朝向进行投票,得到统一的文字行方向 smart_unified: 预测时将除高大于宽两倍的文字行朝向进行投票,得到统一的文字行方向 |
字符串,可选范围 normal unified smart_unified |
normal |
| feature_gather_type | 文字行特征抽取器类型 fixed_size:固定宽高抽取 fixed_height:固定高度并保持宽高比抽取 fixed_height_pyramid:从多尺度的特征中固定高度并保持宽高比抽取 |
字符串,可选范围 fixed_size fixed_height fixed_height_pyramid |
fixed_height |
| feature_gather_aspect_ratio | 文字行的宽高比 当feature_gather_type为fixed_size时,为特征被resize后的宽高比 当feature_gather_type为fixed_height时,为特征resize的最大宽高比约束 |
浮点型 | 40 |
| feature_gather_batch_size | 用于训练的文字行的batch_size | 整型 | 160 |
| recognition_norm_type | 编码器和文字行特征抽取器中norm类型 | 字符串,可选范围 batch_norm group_norm |
group_norm |
| recognition_bn_trainable | 编码器和文字行特征抽取器中的batch norm是否可以训练,当norm_type为batch_norm时生效 | 布尔 | false |
| encoder_type | 编码器类型 crnn: CNN+RNN编码器 cnn_line: CNN编码器 cnn_spatial: CNN编码器,用于spatial attention |
字符串,可选范围 crnn cnn_line cnn_spatial |
crnn |
| encoder_cnn_name | 编码器中使用的cnn类型 | 字符串,可选范围 conv5_encoder senet5_encoder |
senet5_encoder |
| encoder_num_layers | 编码器层数(一般指RNN层数,CNN不计算在内) | 整型 | 2 |
| encoder_rnn_type | 编码器中RNN的类型, bi:双向rnn encoder uni:单向rnn encoder |
字符串,可选范围 bi uni |
uni |
| encoder_hidden_size | 编码器中的隐藏层神经元数目 | 整型 | 512 |
| encoder_cell_type | 编码器中的rnn cell类型 | 字符串,可选范围 basic_lstm gru layer_norm_basic_lstm nas |
basic_lstm |
| decoder_type | 解码器类型 | 字符串,可选范围 attention ctc |
attention |
| decoder_num_layers | 解码器层数 | 整型 | 2 |
| decoder_hidden_size | 解码器中的隐藏层神经元数目 | 整型 | 512 |
| decoder_cell_type | 解码器中的rnn cell类型 | 字符串,可选范围 basic_lstm gru layer_norm_basic_lstm nas |
basic_lstm |
| embedding_size | 字典的embedding大小 | 整型 | 64 |
| beam_width | beam search中的beam width | 整形 | 0 |
| length_penalty_weight | beam search中的length penalty,用于避免短序列倾向 | 浮点数 | 0.0 |
| attention_mechanism | 解码器中的attention类型 | 字符串,可选范围 luong scaled_luong bahdanau normed_bahdanau |
normed_bahdanau |
| aspect_ratio_min_jitter_coef | 训练时随机扰动图像宽高比的最小比例;设置为0,关闭随机扰动图像宽高比 | 浮点数 | 0.8 |
| aspect_ratio_max_jitter_coef | 训练时随机扰动图像宽高比的最大比例;设置为0,关闭随机扰动图像宽高比 | 浮点数 | 1.2 |
| random_rotation_angle | 训练时随机旋转图像的角度,取(-angle, angle)范围内的随机值;设置为0,关闭随机随机旋转图像 |
浮点数 | 10 |
| random_crop_min_area | 训练时随机裁切图像的最小面积占比约束;设置为0,关闭随机随机裁切图像 | 浮点数 | 0.1 |
| random_crop_max_area | 训练时随机裁切图像的最大面积占比约束;设置为0,关闭随机随机裁切图像 | 浮点数 | 1.0 |
| random_crop_min_aspect_ratio | 训练时随机裁切图像的最小宽高比约束;设置为0,关闭随机随机裁切图像 |
浮点数 | 0.2 |
| random_crop_max_aspect_ratio | 训练时随机裁切图像的最大宽高比约束;设置为0,关闭随机随机裁切图像 | 浮点数 | 5 |
| image_min_sizes | 图片缩放大小最短边 为了支持multi-scale training,当输入的size有多个时,前n-1个作为训练的配置,最后一个做评估测试的配置。否则,训练评估使用相同配置。 |
浮点列表 | 800 |
| image_max_sizes | 图片缩放大小最长边 为了支持multi-scale training,当输入的size有多个时,前n-1个作为训练的配置,最后一个做评估测试的配置。否则,训练评估使用相同配置。 |
浮点列表 | 1200 |
| random_distort_color | 是否在训练时随机扰动图片的亮度、对比度、饱和度 | 布尔 | true |
| optimizer | 优化方法,其中momentum就是sgd | 字符串,可选方法如下: momentum adam |
momentum |
| lr_type | 学习率调整策略 exponential_decay, 指数衰减,详细参考tf.train.exponential_decay polynomial_decay, 多项式衰减,详细参考tf.train.polynomial_decay, 其中num_steps自动设置为总的训练迭代次数,end_learning_rate为initial_learning_rate的千分之一 manual_step, 人工指定各阶段的学习率, 通过decay_epochs 指定需要调整学习率的迭代轮数, 通过learning_rates指定对应迭代轮数使用的学习率 cosine_decay,通过余弦曲线调制学习率变化,最终会降到0。详细参考论文, 通过decay_epochs 指定需要调整学习率的迭代轮数 |
字符串,可选方法如下: exponential_decay polynomial_decay manual_step cosine_decay |
exponential_decay |
| initial_learning_rate | 初始学习率 | 浮点数 | 0.01 |
| decay_epochs |
如果使用exponential_decay, 参数对应 tf.train.exponential_decay中的decay_steps,后端会自动根据训练数据总数把decay_epochs转换为decay_steps。例如数值可填:10,一般是总epoch数的1/2。 如果使用manual_step, 参数表示需要调整学习率的迭代轮数, "16 18"表示在16epoch 18 epoch对学习率进行调整。一般这两个值取总设置的总epoch的8/10、9/10 |
整数列表 20 20 40 60 |
20 |
| decay_factor | tf.train.exponential_decay 中的decay_factor | 浮点数 | 0.95 |
| staircase | tf.train.exponential_decay 中的staircase | 布尔 | true |
| power | tf.train.polynomial_decay 中的power | float | 0.9 |
| learning_rates | manual_step学习率调整策略中使用的参数,表示在指定epoch 学习率调整为多少. 如果您指定的调整epoch有两个,则需要在此也填写两个对应的学习率。例:decay_epoches为20 40,此处填写0.001 0.0001,则代表在20epoch学习率调整为0.001,40epoch学习率调整为0.0001。建议这几次调整的学习率是初始学习率的1/10、1/100、1/1000...... | manual_step学习率调整策略中使用的参数,表示在指定epoch 学习率调整为多少 | 浮点列表 |
| lr_warmup | 是否对学习率做warmup | 布尔 | false |
| lr_warm_up_epochs | 学习率warmup的轮数 | 浮点型 | 1 |
| train_data | 训练数据文件oss路径 | oss://path/to/train_*.tfrecord | 无,必选参数 |
| test_data | 训练过程中评估数据oss路径 | oss://path/to/test_*.tfrecord | 无,必选参数 |
| train_batch_size | 训练batch_size | 整型, 例如32 | 无,必选参数 |
| test_batch_size | 评估batch_size | 整型, 例如32 | 无,必选参数 |
| train_num_readers | 训练数据并发读取线程数 | 整型 | 4 |
| model_dir | 训练所用oss目录 | oss://path/to/model | 无,必选参数 |
| pretrained_model | 预训练模型oss路径,如果提供,会在此模型基础上finetune | oss://pai-vision-data-hz/pretrained_models/inception_v4.ckpt | "" |
| use_pretrained_model | 是否使用预训练模型 | 布尔型 | true |
| num_epochs | 训练迭代轮数,1表示所有训练数据过了一遍 | 整型 40 | 无,必选参数 |
| num_test_example | 训练过程中评估数据条目数, -1表示使用所有测试数据集数据 | 整型,例如2000 | 可选,默认-1 |
| num_visualizations | 评估过程可视化显示的样本数目 | 整型 | 10 |
| save_checkpoint_epochs | 保存checkpoint的频率,以epoch为单位, 1表示每过一遍训练数据保存一次checkpoint | 整型 | 1 |
| save_summary_epochs | 保存summary的频率,以epoch为单位, 0.01 表示每过1%训练数据保存一次summary | 浮点 | 0.01 |
| num_train_images | 总的训练样本数,如果使用自己生成的tfrecord需要提供该信息 | 整型 | 可选,默认0 |
| label_map_path | 类别映射文件,如果使用自己生成的tfrecord需要提供该信息 | 字符串 | 可选,默认"" |