流量调控¶
参见
流量调控算法原理请参考 《 流量调控算法原理 》。
注册数据源¶
注册AccessKey。 页面:配置中心——基础配置——AK管理——新增。
添加数据源。页面:配置中心——基础配置——数据源管理——新增。
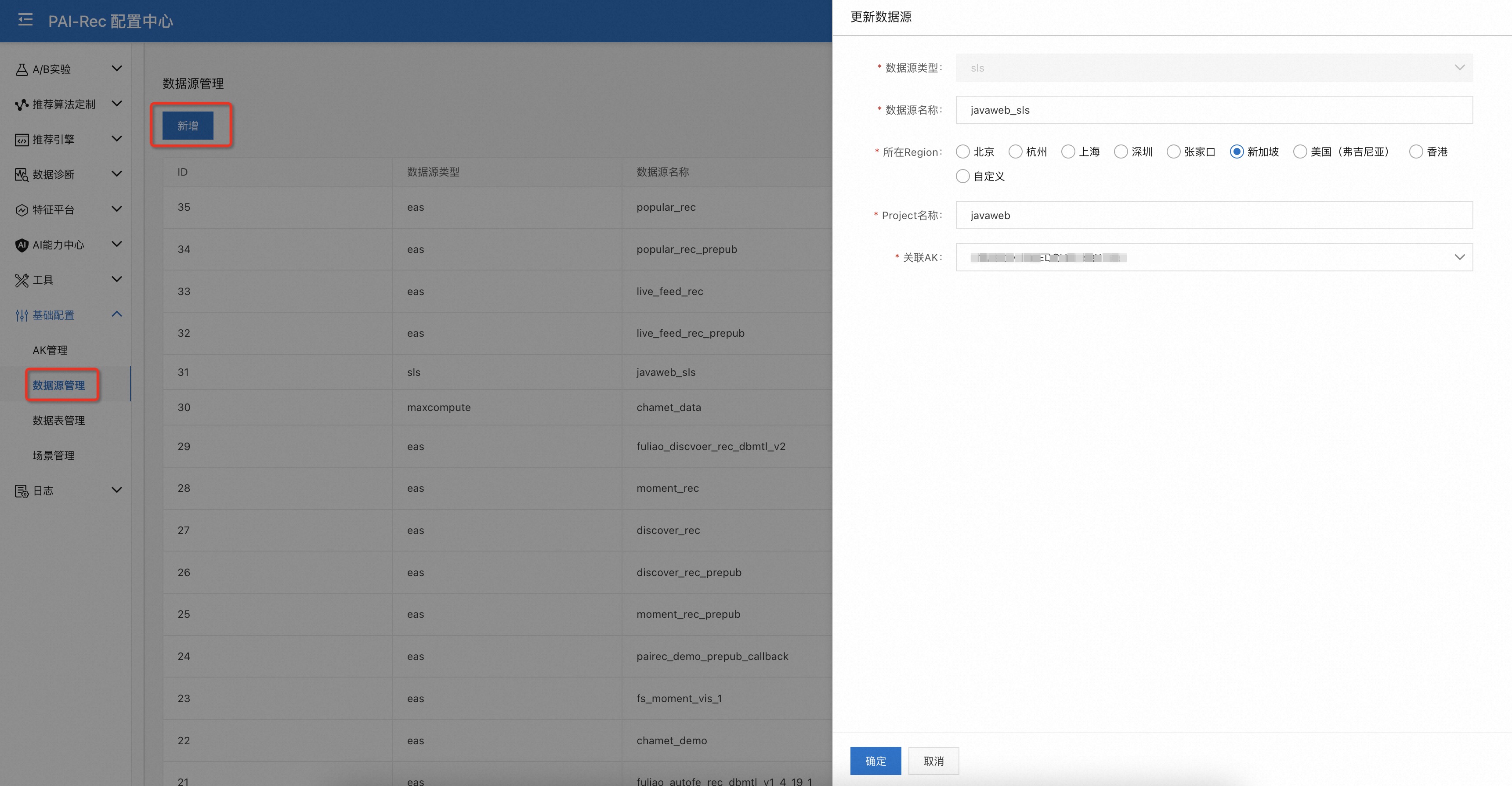
至少需要注册两个数据:
实时行为日志的消息中间件,如kafka、sls、datahub等;
用于存放item属性信息的 Hologres 。
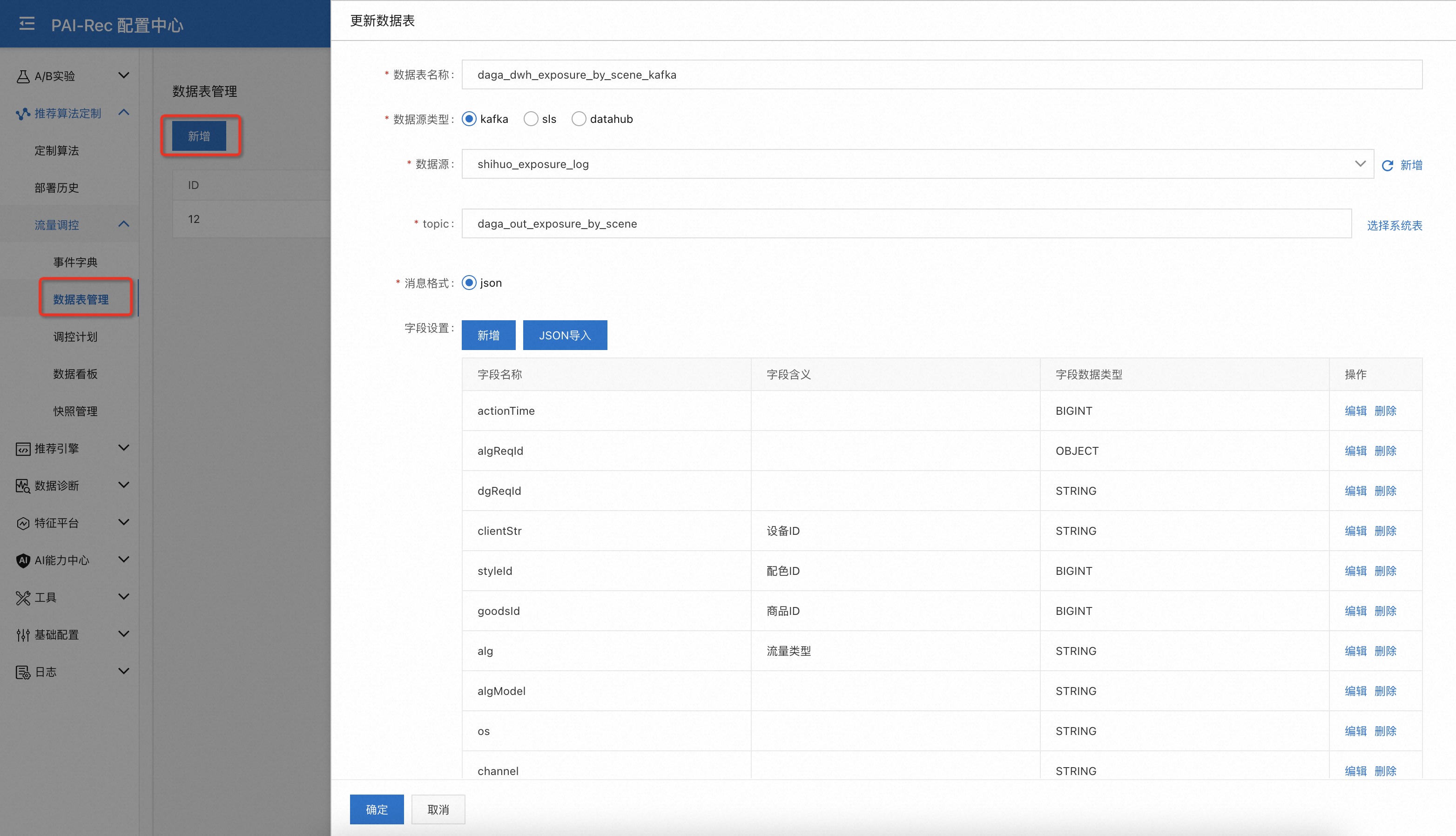
新增数据表¶
添加用于统计流量信息的实时数据表。需要编辑数据表的schema信息,嵌套的字段可以把字段类型定义为OBJECT。
也可以用JSON导入功能从一条json格式的日志自动解析出schema信息。
页面:配置中心——推荐算法定制——流量调控——数据表管理——新增
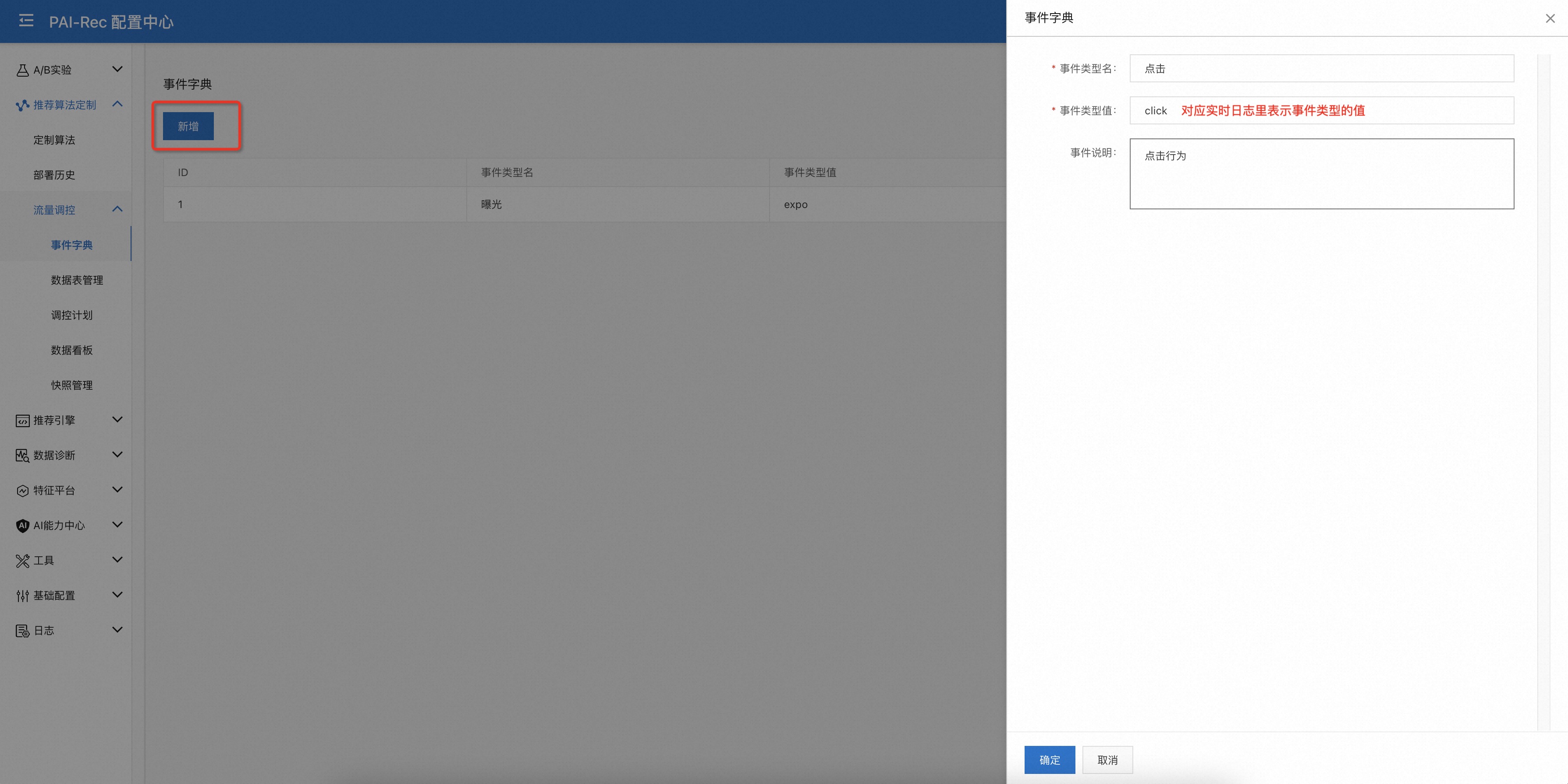
定义调控事件¶
页面:配置中心——推荐算法定制——流量调控——事件字典——新增
定义需要调控的行为类型,如曝光、点击等。这里事件类型值需要跟实时行为日志(kafka、sls、datahub等)中表示事件类型的值一致。
创建调控计划¶
页面:配置中心——推荐算法定制——流量调控——调控计划——新增
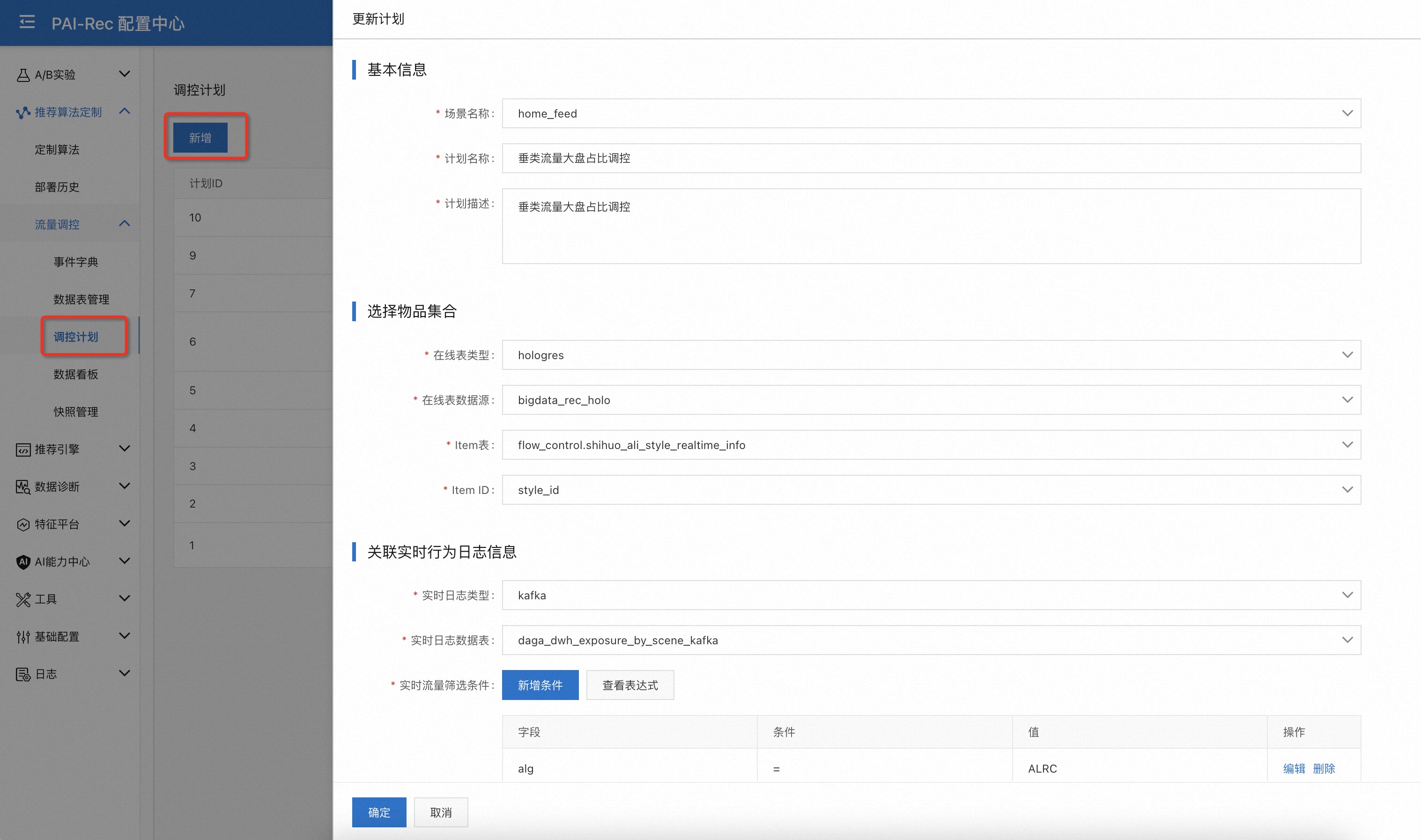
选择推荐场景,添加调控计划的基本信息;
定义调控计划关联的Item集合,目前只能从
hologres数据源选择一张数据表(Item表),并且需要设置ItemId字段;Item表用来判断被推荐算法召回的物品是否是被调控的对象
Item表可实时更新,实现动态调控目标
关联实时行为日志信息,选择注册好的实时行为日志表,并且可以设置日志表的过滤条件;
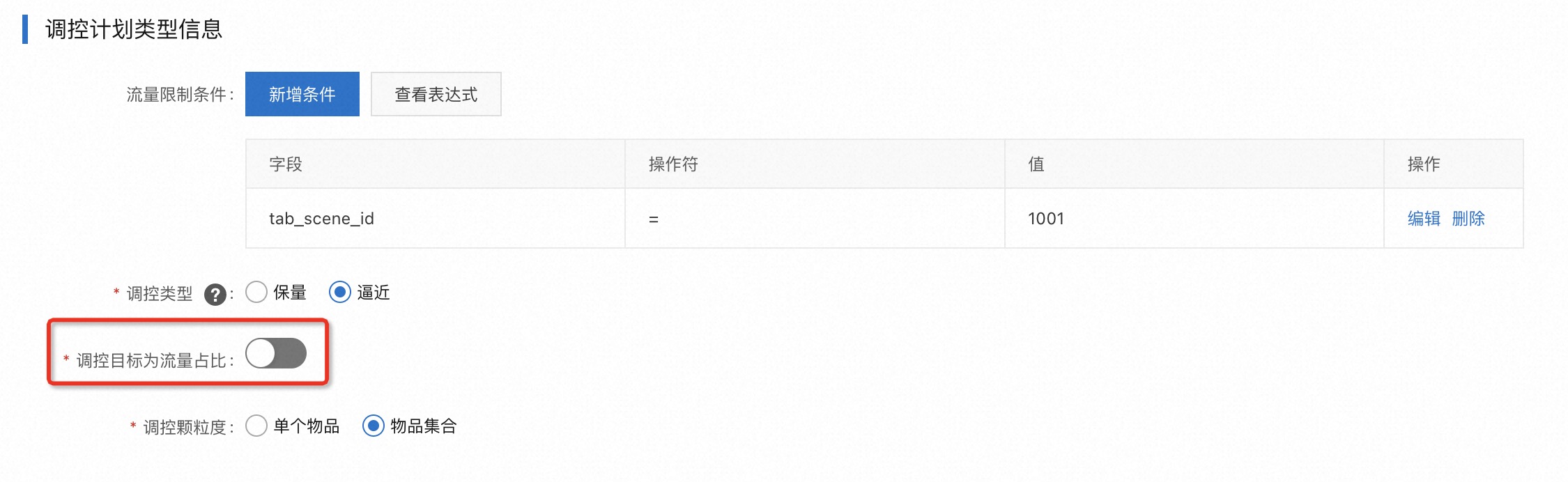
填写调控计划类型信息,可以添加流量限制条件,即只对特定的流量做调控,不满足配置条件的流量不被调控;
调控类型有
保量、逼近两种。保量:调控任务致力于让目标物品集获得大于等于设定目标值的流量;
逼近:调控任务致力于让目标物品集获得约等于设定目标值的流量; 备注:当多个“逼近”类型的调控任务关联了相同的物品子集时可能会存在因目标冲突而无法达成目标的情况。
调控目标类型有
绝对值、流量占比两种当调控目标为
流量占比时,可以设置作为流量大盘的物品集合筛选条件,若不配置默认用所有符合条件的大盘流量作为流量占比的分母当调控目标为
绝对值时,可以选择调控颗粒度为物品集合或单个物品

添加调控目标¶
可以为每个调控计划添加多个调控目标,这些调控目标共享相同的计划元信息。
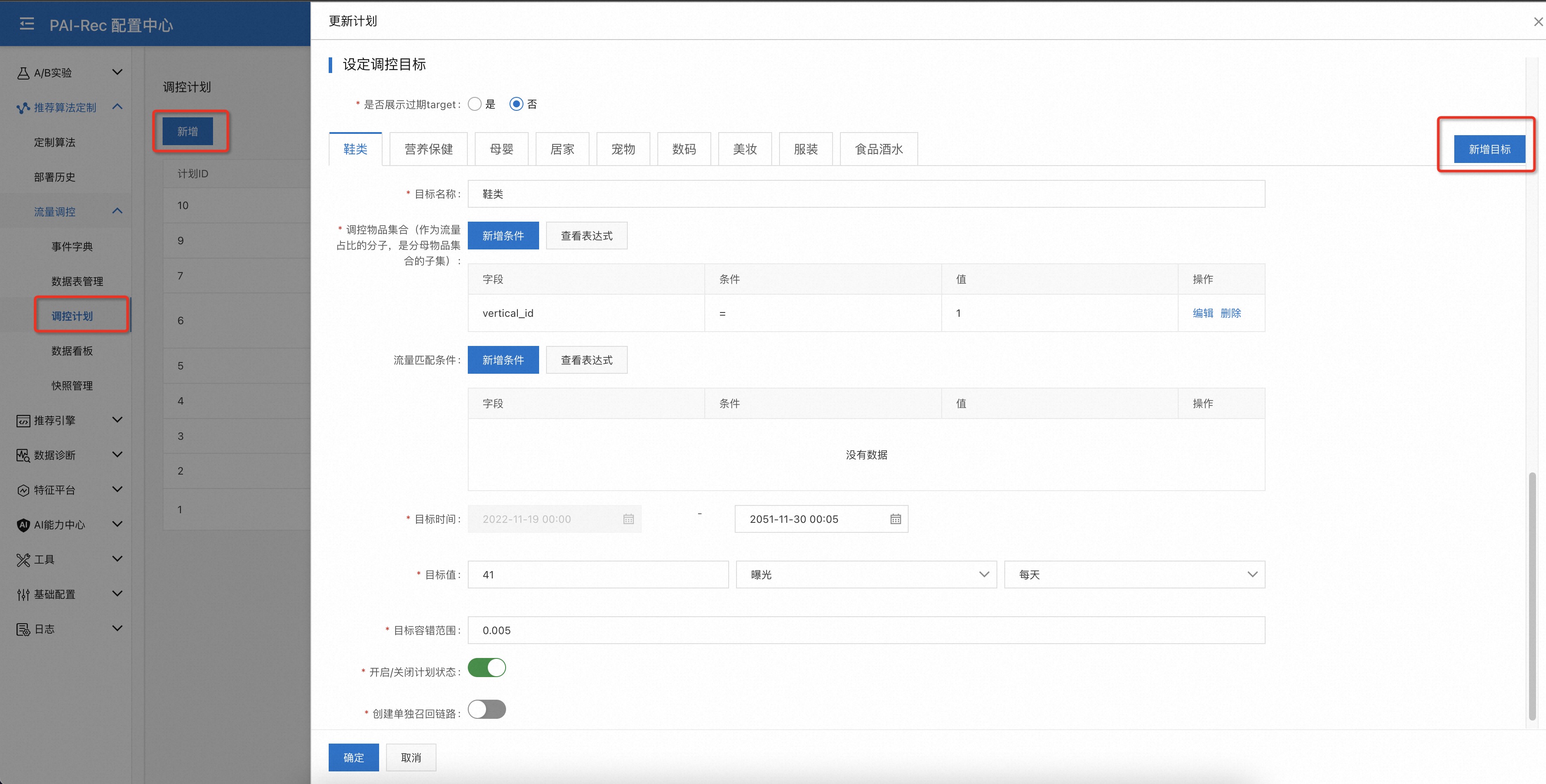
每个调控目标需要设定当前目标关注的物品集合筛选条件,也就是Item表的字段查询条件;
调控目标可以选择流量匹配条件,比如只对男性用户做调控;
调控目标需要设定调控的开始时间与结束时间;
必须要设定调控目标值,目标值有
绝对值、流量占比两种类型;并且需要为目标值关联某个行为事件;可选的目标容错范围指当实际流量与目标流量的Gap在设定的范围内时,停止调控;
计划状态的开启与关闭开关决定当前计划是否生效;
当目标关联的物品集合非常冷门时,需要创建单独的召回链路,请打开
创建单独召回链路的开关。
提示
是否给目标内容boost越多越有利?
好处:排序位置 提升越多,曝光次数越多
坏处:【拔苗助长、物极必反】把目标内容推荐给不太合适的受众
点击率、点赞率等指标会偏低
长期会受推荐系统打压,难以成长为热门内容
建议:进行差异化保量
基础保量:普通内容
差异化保量:优质内容、优质作者
需要一个质量分评估模型:如:商品人气分模型
参见
动态更新调控目标
PaiRec 支持通过API的方式动态更新调控目标的内容,如设置目标值,详见下文!
案例¶
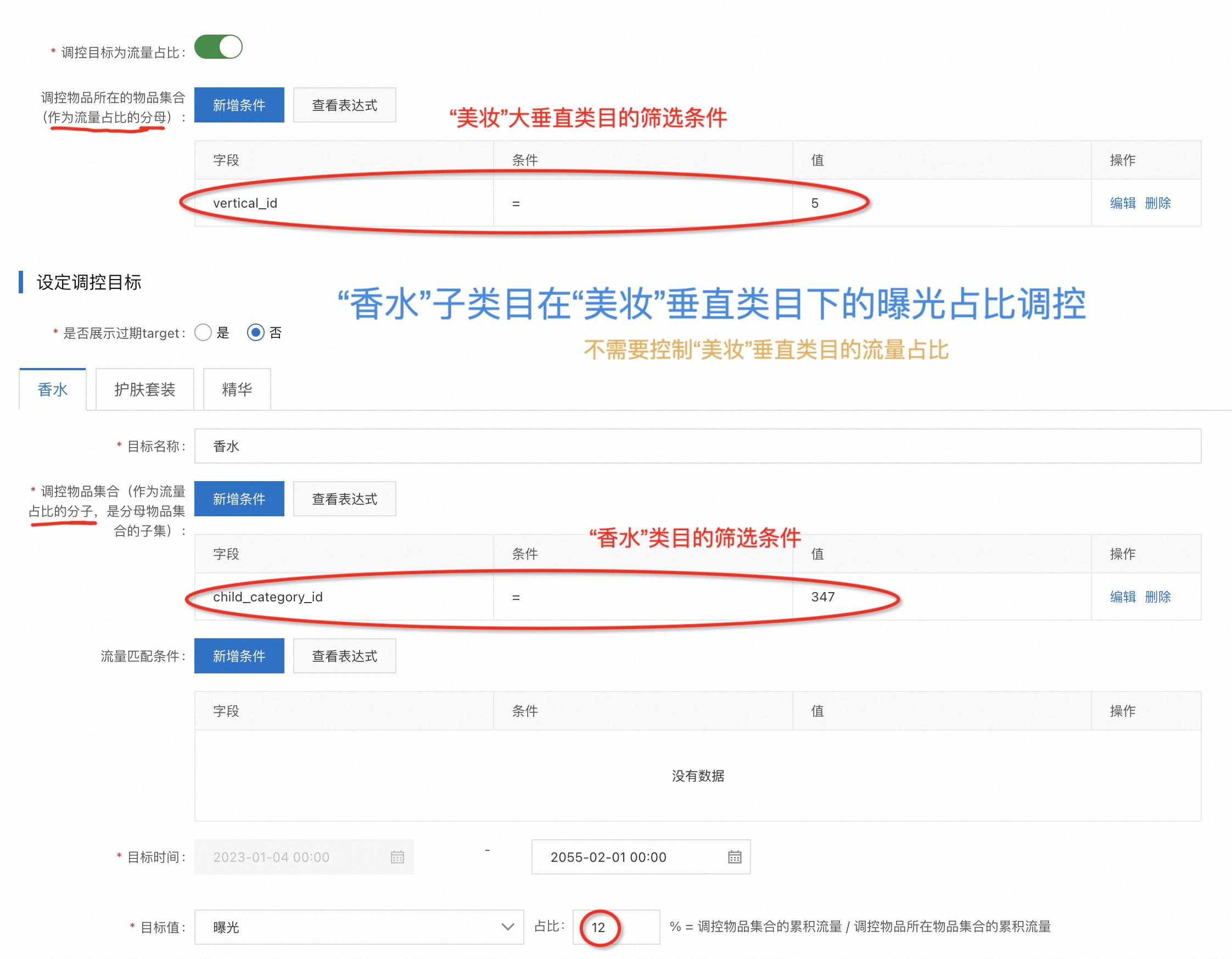
目标:控制”香水”子类目在”美妆”大类目下的曝光占比为12%;要求不干预”美妆”大类目在大盘的流量占比。
推荐服务添加流控配置¶
在PaiRec推荐引擎配置管理页面添加流控和打散的配置。
{
"SortConfs": [
{
"Name": "PositionReviseSort",
"SortType": "PositionReviseSort",
"PIDConf": {
"SyncPIDStatus": true,
"HologresName": "pairec-holo",
"RedisName": "redis-cache",
"RedisKeyPrefix": "pid_",
"LoadItemFeature": true,
"PreloadItemFeature": true,
"MaxItemCacheSize": 500000,
"MaxItemCacheTime": 3600,
"SampleTime": 30,
"DefaultKp": 0.01,
"DefaultKi": 0.01,
"DefaultKd": 1,
"AllocateExperimentWise": false
}
},
{
"Name": "DiversitySort",
"SortType": "DiversityRuleSort",
"DiversityRules": [
{
"Dimensions": [
"__flow_control_id__"
],
"WindowSize": 5,
"FrequencySize": 1
}
]
}
],
"SortNames": {
"default": [
"PositionReviseSort",
"DiversitySort"
]
}
}
PositionReviseSort 流量调控模块的参数:
SyncPIDStatus: 是否在不同实例间同步PID算法的中间状态
HologresName: hologres链接配置项名称
RedisName: redis链接配置项名称;redis用来同步PID算法的中间状态
RedisKeyPrefix: redis key的前缀
MaxItemCacheSize: redis缓存大小
MaxItemCacheTime: redis缓存时间
LoadItemFeature: 是否需要加载Item属性信息用于判断是否为调控对象,默认需要
SampleTime 为PID算法重新计算调控输出信号的时间间隔
DefaultKp, DefaultKi, DefaultKd 为 PID 算法的三个默认参数值:\(K_P,K_I,K_D\),可通过A/B实验配置覆盖
AllocateExperimentWise 是否按照实验粒度来调控的开关,打开后每个实验桶都需达成目标;关闭后仅保证整体达成目标
DiversityRuleSort 是打散插件,用来配置Item的打散逻辑。
每个被流控模块上提的item都有一个
__flow_control_id__属性,其值为常量0;其他未被干预的item的__flow_control_id__为一个不重复的数字id值。该案例中的配置保证了每5个坑位中最多只能展示1个被流量调控模块上提的item。
提示
先发布推荐引擎中的流控和打散配置,再到流控Web UI上发布调控计划/目标 PositionReviseSort 模块内部会实现Item分数的降序排列;如果调控计划未发布,该模块不会产生其他副作用。
部署流量统计任务¶
实时流量统计任务部署在flink平台上,后续版本会自动部署。目前请联系PaiRec团队协助部署。
发布调控计划/目标¶
调控计划及目标编辑完成后,默认不生效,需要保存快照并发快照发布到预发/生产环境后,调控计划/目标才能生效。
注意
只有在严格按照文档的顺序执行完前面的所有步骤后,才能执行流控任务的发布。
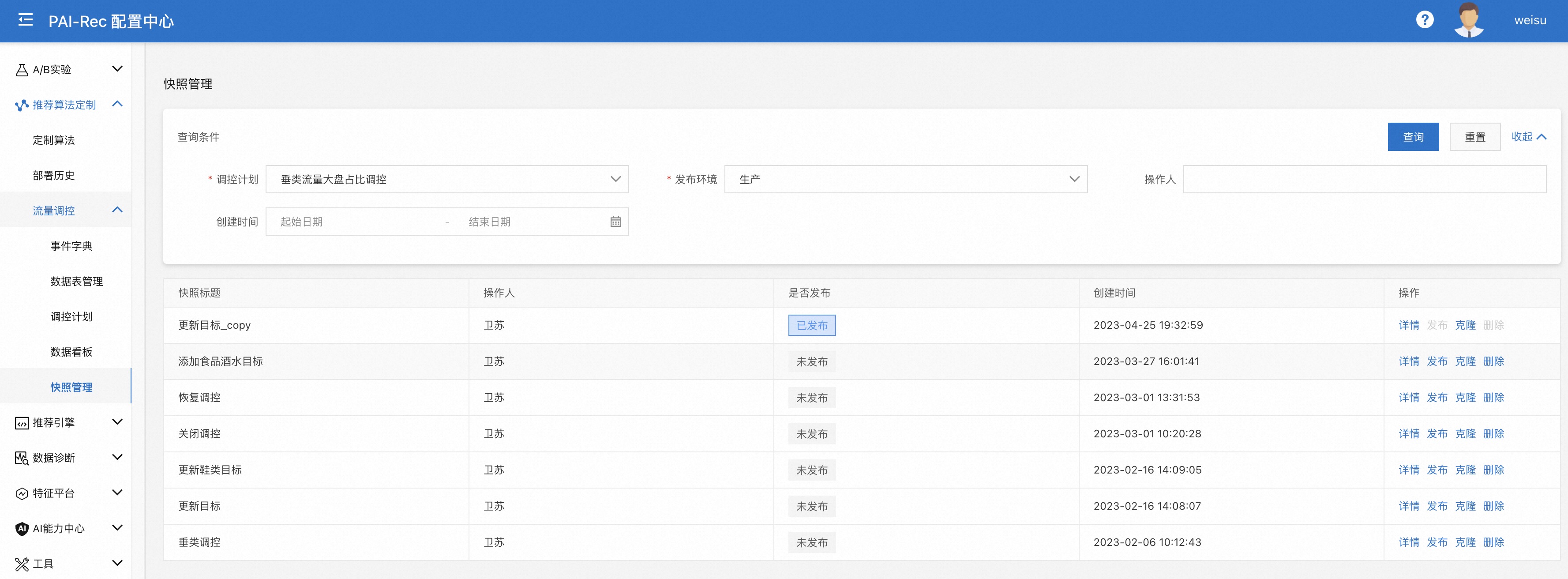
页面:配置中心——推荐算法定制——流量调控——调控计划——保存快照
可以在保存快照的同时发布,可以在快照管理页面发起发布流程。
快照管理页面可查看发布记录,页面:配置中心——推荐算法定制——流量调控——调控计划——快照管理
流量调控AB实验配置¶
在基准桶中关闭流量调控功能
{
"pid_control_enable": 0
}
危险
在流量统计的flink任务中需要过滤掉基准桶的流量,因其不参与流量调控,统计该桶的流量会影响其他桶的目标达成。
在实验桶中配置各个调控目标的参数
{
"pid_beta": 2,
"pid_params": {
"default": {
"start_page_num": 2,
"kp": 10000,
"ki": 10,
"kd": 1,
"err_discount": 0.95
},
"1": {
"start_page_num": 1,
"min_exp_traffic": 1000,
"allocate_exp_wise": true,
"err_discount": 0.99,
"kp": 10000,
"ki": 200,
"kd": 500
},
"2": {
"start_page_num": 2,
"allocate_exp_wise": false,
"min_exp_traffic": 200,
"err_discount": 0.99,
"kp": 200000,
"ki": 1000,
"kd": 100
},
"3": {
"online": true
}
}
}
如上,在配置项pid_params下可配置默认的PID参数;也可为某个具体的调控目标(用数字ID表示)配置单独的参数。
start_page_num: 从第几页的请求开始调控,默认从第一页开始
err_discount:目标累计误差的时间步折扣因子,默认值为1.0
kp,ki,kd:PID算法差分、积分、微分项系数
allocate_exp_wise: 是否需要按实验桶调控;建议流量高的目标按实验桶调控,小流量目标按整体调控
online: 开启/关闭 某个调控目标
小技巧
如何获取调控计划ID?如何获取调控目标ID?
调控计划的ID在
配置中心——推荐算法定制——流量调控——调控计划页面可以查看。查看某个调控计划(该案例中计划ID为1)下面的所有调控目标信息,在Bash中执行如下命令:
curl -H ‘Authorization:${AuthCode}’ ‘http://${host}/api/predict/pairec_cn_tl32vqgpw01_pairec_experiment/v1/flow_ctrl_plans/1?without_traffic=true&without_outdated_target=true’
这里的请求URL以及授权码请在PaiRec服务的EAS配置中查看。
在实验组配置中添加全局参数
{
"pid_experiment_layer": "L1#",
"pid_eta": 2.0
}
pid_experiment_layer: 流量实验层号前缀;当有多个实验桶时必须要配置
参见
其他参数请参考调控公式
查看调控结果¶
页面:配置中心——推荐算法定制——流量调控——调控计划——数据看板

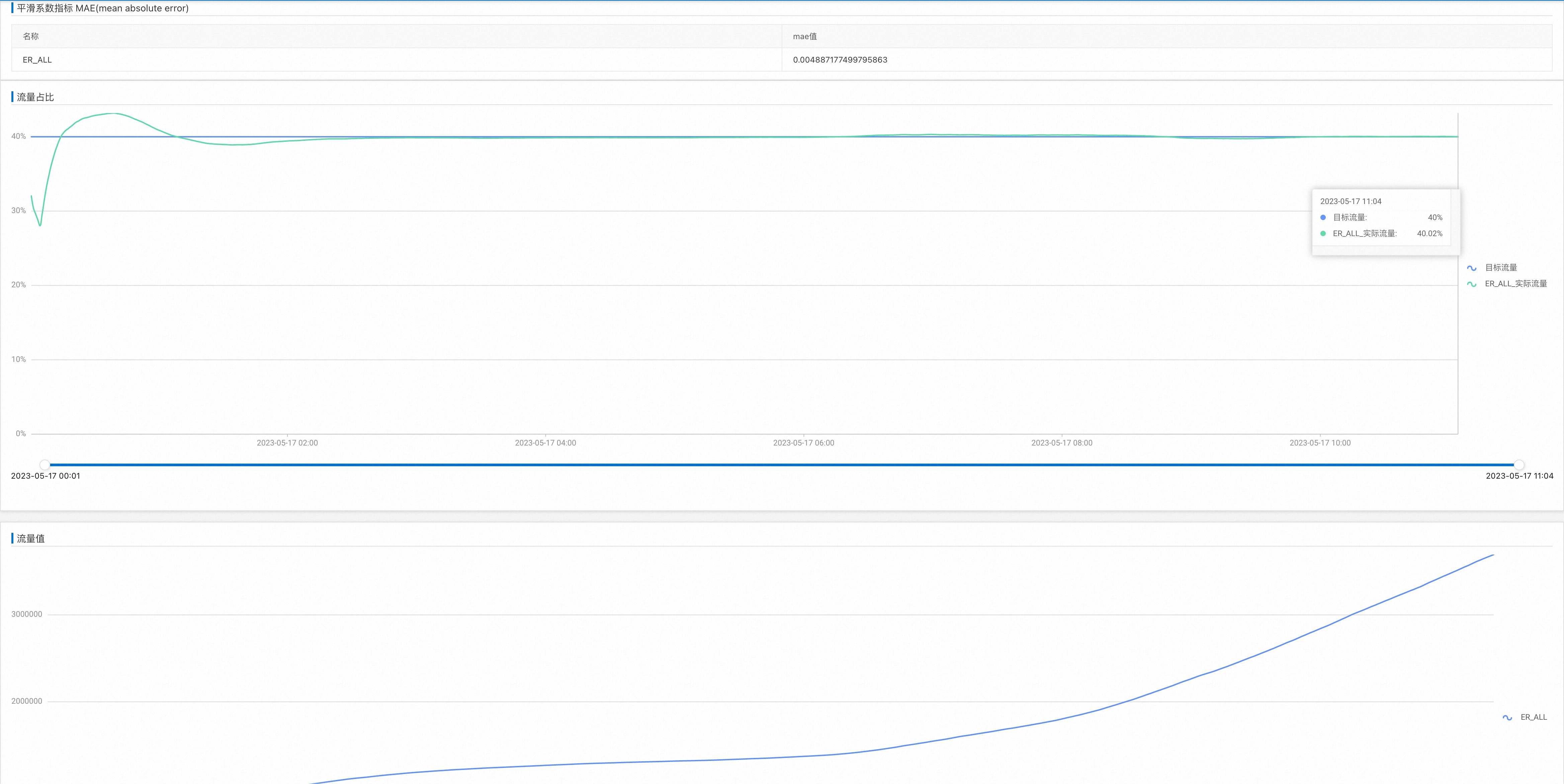
动态调整调控信息¶
当需要从外部系统同步调控任务的基本信息(对调控任务进行增、删、改、查)时,可以通过配置中心Server提供的Http接口来完成。 比如需要新增调控计划,或者对已有调控任务修改调控目标值,可以通过这种方式进行。
备注
更推荐运营人员直接在配置中心—推荐算法定制-流量调控-调控计划页面上对任务进行变更,省去中间复杂的步骤!
在DataWorks上新建一个 PyOdps 3类型的任务,参考如下示例代码部署一个定时调度的任务即可。
# coding: utf-8
import requests
import copy
import json
import sys
import time
header = {
'Authorization': '${AuthCode}',
'Content-Type': 'application/json'
}
def get_exist_targets():
url = 'http://1104944991506609.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/pairec_cn_tl32vqgpw01_pairec_experiment/v1/flow_ctrl_plans/6?env=product&without_traffic=true&without_outdated_target=true'
r = requests.get(url, headers=header)
if not r.ok:
return None, r.ok
msg = json.loads(r.content)
targets = {x['target_name']: x for x in msg['data']['plan']['targets']}
return targets, True
exist_targets, ok = get_exist_targets()
if not ok:
print('get exist targets failed')
sys.exit(1)
print('exist targets:', json.dumps(exist_targets))
print()
print()
bizhour=args['bizhour']
gmtdate=args['gmtdate']
# 获取全量计划(仅包含调控时间包含今天全天的)
sql = """
select tag_name, exp_al_num, tag_cnt, min(start_time_timestamp), max(end_time_timestamp)
from ${traffic_control_meta_info_table}
where dt={bizhour}
AND start_time <= to_date('{gmtdate}', 'yyyymmdd')
AND end_time >= to_date('{gmtdate} 23:59:59', 'yyyymmdd hh:mi:ss')
GROUP BY tag_name, exp_al_num, tag_cnt;
""".format(bizhour=bizhour, gmtdate=gmtdate)
print("sql=" + sql)
print()
plan = {
"plan_id": 6,
"scene_id": 2,
"scene_name": "home_feed",
"plan_name": "style_id粒度的聚合调控计划",
"plan_desc": "style_id粒度的聚合调控计划",
"online_datasource_type": "hologres",
"online_datasource_id": 4,
"online_table_name": "flow_control.alg_boost_goods",
"online_table_item_id_field": "id",
"plan_scope_filter": "",
"plan_scope_filter_json": "[]",
"target_value_in_percentage_format": False,
"plan_type": "guaranteed",
"granularity": "single",
"load_traffic_by_plan": True,
"realtime_log_type": "kafka",
"realtime_log_table_meta_id": 12,
"RealtimeLogFilter": "alg = ALRC AND sceneId = 1001",
"realtime_log_filter_json": "[{\"field\":\"alg\",\"option\":\"=\",\"value\":\"ALRC\"},{\"field\":\"sceneId\",\"option\":\"=\",\"value\":\"1001\"}]",
"flow_scope_filter_json": "[{\"field\":\"tab_scene_id\",\"option\":\"=\",\"value\":\"1001\"}]",
"status": "enable"
}
target_template = {'planId': 6, 'target_type':1, 'time_unit': 'daily', 'set_point_range':0, 'do_recall': True, 'status': 'enable', 'item_scope_filter_json': '[]'}
scope = '[{"field":"tag_cnt","option":"=","value":"%d"},{"field":"exp_al_num","option":"=","value":"%d"},{"field":"tag_name","option":"=","value":"%s"}]'
plan_targets = {}
with o.execute_sql(sql).open_reader(tunnel=True, limit=False) as reader:
for record in reader:
tag_name, expo, tag_cnt, start, end = record[:]
name = '%s/%d/%d' % (tag_name, expo, tag_cnt)
t = expo//tag_cnt
if expo%tag_cnt != 0:
t += 1
t += 10 # 防止目标达不成
plan_targets[name] = (expo, tag_cnt, t, start, end, tag_name)
if len(plan_targets) <= 0:
print("no target need to be updated")
sys.exit(0)
targets = []
for name, value in plan_targets.items():
target = copy.deepcopy(target_template)
if name in exist_targets:
target['target_id'] = exist_targets[name]['target_id']
target['target_name'] = name
target['set_point'] = value[2]
target['target_scope_filter'] = 'tag_cnt = %d AND exp_al_num = %d AND tag_name = %s' % (value[1], value[0], value[5])
target['target_scope_filter_json'] = scope % (value[1], value[0], value[5])
target['start_time'] = int(value[3]/1000)
target['end_time'] = int(value[4]/1000)
targets.append(target)
# 关闭旧计划
for name, target in exist_targets.items():
if name in plan_targets:
continue
if target['status'] == 'disable':
continue
target['status'] = 'disable'
t = {x:target[x] for x in target_template if x != 'time_unit'}
t['time_unit'] = target['time_uint']
t.update({x:target[x] for x in ['target_id', 'target_name', 'set_point', 'target_scope_filter', 'target_scope_filter_json']})
targets.append(t)
plan['targets'] = targets
body = json.dumps(plan, ensure_ascii=False)
print("update request body:", body)
print()
url = 'http://1104944991506609.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/pairec_cn_tl32vqgpw01_pairec_experiment/v1/flow_ctrl_plans/6'
r = requests.post(url, data=body.encode('utf-8'), headers=header)
print(r.text)
if not r.ok:
sys.exit(1)
print()
print()
time.sleep(60) # sleep 1 min
#----------------------[release to prepub environment]------------------------------------
snapshot = {'plan_id': 6, 'env': 'prepub', 'title': '%s update' % bizhour, 'note': 'from dataworks', 'release_now': True}
body = json.dumps(snapshot)
print("release request body:", body)
print()
url = 'http://1104944991506609.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/pairec_cn_tl32vqgpw01_pairec_experiment/v1/flow_ctrl_snapshots'
r = requests.post(url, data=body, headers=header)
print(r.text)
print()
print()
time.sleep(10) # sleep 10 secs
#----------------------[release to product environment]------------------------------------
snapshot = {'plan_id': 6, 'env': 'product', 'title': '%s update' % bizhour, 'note': 'from dataworks', 'release_now': True}
body = json.dumps(snapshot)
print("release request body:", body)
print()
url = 'http://1104944991506609.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/pairec_cn_tl32vqgpw01_pairec_experiment/v1/flow_ctrl_snapshots'
r = requests.post(url, data=body, headers=header)
print(r.text)
print()
动态调整阶段性拆解目标¶
参见
为什么需要动态调整阶段性拆解目标请参考 《 流量调控算法原理 》。
步骤:
用流量预估模型或直接统计历史平均值的方式对目标物品池的阶段性累计目标进行预估;
采用如下脚本把预估的结果同步给PaiRec流量调控系统;
# coding: utf-8
import requests
# import copy
import json
import sys
from odps.df import DataFrame
bizdate=args['bizdate']
ratio = DataFrame(o.get_table('traffic_volume_moving_average').get_partition('dt='+bizdate))
ratio = ratio.sort('time_point')
# print(ratio.head(48))
expo_ratio = []
for row in ratio['time_point', 'expo_ratio'].head(48):
expo_ratio.append((int(row['time_point']), row['expo_ratio']))
print('----------------traffic------------------')
print(expo_ratio)
header = {
'Authorization': '${AuthCode}',
'Content-Type': 'application/json'
}
def get_exist_targets():
url = 'http://1104944991506609.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/pairec_cn_tl32vqgpw01_pairec_experiment/v1/flow_ctrl_plans/6?without_traffic=true&without_outdated_target=true'
r = requests.get(url, headers=header)
if not r.ok:
return None, r.ok
msg = json.loads(r.content)
targets = {x['target_id']: x for x in msg['data']['plan']['targets']}
return targets, True
exist_targets, ok = get_exist_targets()
if not ok:
print('get exist targets failed')
sys.exit(1)
targets = {}
for tid, target in exist_targets.items():
if target['status'] == 'disable':
continue
set_point = target['set_point']
values = { "env": 1}
time_points = [x[0] for x in expo_ratio]
set_points = [x[1] * set_point for x in expo_ratio]
values["time_points"] = time_points
values["set_points"] = set_points
targets[str(tid)] = values
if len(targets) <= 0:
print("no target need to be updated")
sys.exit(0)
body = json.dumps(targets, ensure_ascii=False)
print("prepub request body:", body)
print()
#----------------------[release to prepub environment]------------------------------------
url = 'http://1104944991506609.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/pairec_cn_tl32vqgpw01_pairec_experiment/v1/flow_ctrl_plan_targets'
r = requests.post(url, data=body.encode('utf-8'), headers=header)
print(r.text)
print()
print()
#----------------------[release to product environment]------------------------------------
for t, v in targets.items():
v["env"] = 2
body = json.dumps(targets, ensure_ascii=False)
print("product request body:", body)
print()
print()
url = 'http://1104944991506609.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/pairec_cn_tl32vqgpw01_pairec_experiment/v1/flow_ctrl_plan_targets'
r = requests.post(url, data=body, headers=header)
print(r.text)
在DataWorks上新建一个 PyOdps 3类型的任务,参考如上示例代码部署一个定时调度的任务即可。