特征平台 Python SDK 操作¶
以下介绍的所有代码,均可在 Python Notebook 中直接运行。
云端 Python Notebook 运行见 阿里云 DSW Gallery:
本地运行
下载上述文件,本地配置好 python notebook 环境后,即可运行。
1. 安装 Feature Store Python SDK¶
pip install https://feature-store-py.oss-cn-beijing.aliyuncs.com/package/feature_store_py-latest-py3-none-any.whl
2. 导入需要的功能模块¶
import unittest
import sys
import os
from os.path import dirname, join, abspath
from feature_store_py.fs_client import FeatureStoreClient
from feature_store_py.fs_project import FeatureStoreProject
from feature_store_py.fs_datasource import UrlDataSource, MaxComputeDataSource, DatahubDataSource, HologresDataSource, SparkDataSource, LabelInput, TrainingSetOutput
from feature_store_py.fs_type import FSTYPE
from feature_store_py.fs_schema import Schema, Field
from feature_store_py.fs_feature_view import FeatureView
from feature_store_py.fs_features import FeatureSelector
from feature_store_py.fs_config import EASDeployConfig, LabelInputConfig, PartitionConfig, FeatureViewConfig, TrainSetOutputConfig
import logging
logger = logging.getLogger("foo")
logger.addHandler(logging.StreamHandler(stream=sys.stdout))
3. 样例使用的数据集介绍¶
我们使用的是开源电影数据集 Moviedata-10M,数据集官网:http://moviedata.csuldw.com 其中主要使用的是 movie 数据,user 数据,rating 数据。这三份数据可以对应推荐流程中的物料表、用户表、label 表。 我们将展示如果使用 Feature Store 方便的将三份数据的特征整合在一起离线训练模型,并且完成后续上线服务。
4. 项目空间 (Project)¶
我们可以通过 project 可以创建多个项目空间,每个项目空间是独立的。project 里会配置基本的信息,每个 project 会对应一个 OfflineStore 和 OnlineStore。
运行 notebook 需要 feature store server 端配合运行,购买完 PAI-REC (https://www.aliyun.com/activity/bigdata/airec/pairec) 配置中心实例后,在配置中心左侧边栏基础配置-数据源管理页面 (如下图所示) 可以看到服务接口地址 (host) 和 token.
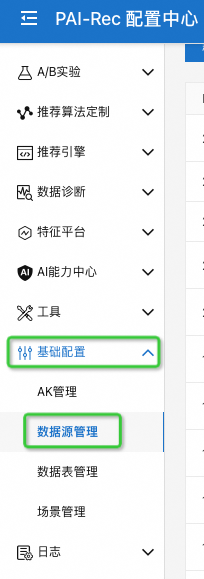
还需要再配置好离线数据源和在线数据源,具体可以参考:特征平台网页操作
然后就可以继续执行操作:
host = ""
token = ""
fs = FeatureStoreClient(host, token)
cur_project_name = "fs_movie_1"
offline_datasource_id = 64
online_datasource_id = 65
project = fs.get_project(cur_project_name)
if project is None:
project = fs.create_project(cur_project_name, offline_datasource_id, online_datasource_id)
其中 host, token, offline_datasource_id, online_datasource_id 都需要从数据源管理中获取。offline_datasource_id 一般是指 max compute, spark (datascience 平台) 等,online_datasource_id 一般是指 hologres, igraph, redis 等。
然后可以获取对应的 project:
project = fs.get_project(cur_project_name)
打印该 project 的信息:
project.print_summary()
5. 特征实体 (Feature Entity)¶
FeatureEntity 描述了一组相关的特征集合。多个 FeatureView 可以关联一个 FeatureEntity。 每个Entity 都会有一个 Entity JoinId , 通过 JoinId 可以关联多个 FeatureView 特征。每一个 FeatureView 都有一个主键(索引键)来获取其下面的特征数据,但是这里的索引键可以和 JoinId 定义的名称不一样。 这里我们创建 movie_data, user_data, rating_data 三个 Entity。
cur_entity_name_movie = "movie_data"
join_id = 'movie_id'
entity_id = None
entity_id = project.get_entity(cur_entity_name_movie)
if entity_id is None:
entity_id = project.create_entity(name = cur_entity_name_movie, join_id=join_id)
print("entity_id = ", entity_id)
获取对应的 entity:
feature_entity = project.get_entity_body(cur_entity_name_movie)
打印该 entity 的信息:
feature_entity.print_summary()
然后我们以类似的方式,创建 user_data 和 rating_data 对应的 entity.
cur_entity_name_user = "user_data"
join_id = 'user_md5'
entity_id = None
entity_id = project.get_entity(cur_entity_name_user)
if entity_id is None:
entity_id = project.create_entity(name = cur_entity_name_user, join_id=join_id)
print("entity_id = ", entity_id)
cur_entity_name_ratings = "rating_data"
join_id = 'rating_id'
entity_id = None
entity_id = project.get_entity(cur_entity_name_ratings)
if entity_id is None:
entity_id = project.create_entity(name = cur_entity_name_ratings, join_id=join_id)
print("entity_id = ", entity_id)
6. 特征视图 (Feature View)¶
FeatureStore是一个特征管理平台,当外部的数据进入到 FS 中, 需要通过 FeatureView。 FeatureView 指定了数据从哪里来(DataSource), 数据进入FS 需要哪些转换(特征工程/Transformation), 特征 schema (特征名称+类型),数据需要放到哪里(OnlineStore/OfflineStore)、特征meta(主键、事件时间、分区键, FeatureEntity, ttl (默认 -1 为无效,设置为正数后,在线查询特征默认会取 ttl 内的特征数据))。
FeatureView 会分为两种类型, BatchFeatureView 和 StreamFeatureView 。 BatchFeatureView 可以把离线数据注入到 FS 中, StreamFeatureView 支持实时特征的写入。 BatchFeatureView 会把数据管理到 OfflineStore 里, 然后可以选择同步到 OnlineStore 里。StreamFeatureView 会把数据写入到 OnlineStore 里,然后同步到 OfflineStore 里。
在这里我们先展示一下 BatchFeatureView 的操作。目前我们的数据是存在于 csv 文件中,通过 url 下载。
path = 'https://feature-store-test.oss-cn-beijing.aliyuncs.com/dataset/moviedata_all/movies.csv'
delimiter = ','
omit_header = True
ds = UrlDataSource(path, delimiter, omit_header)
print(ds)
然后我们通过 schema 定义字段的名称和类型。
movie_schema = Schema(
Field(name='movie_id', type=FSTYPE.STRING),
Field(name='name', type=FSTYPE.STRING),
Field(name='alias', type=FSTYPE.STRING),
Field(name='actores', type=FSTYPE.STRING),
Field(name='cover', type=FSTYPE.STRING),
Field(name='directors', type=FSTYPE.STRING),
Field(name='double_score', type=FSTYPE.STRING),
Field(name='double_votes', type=FSTYPE.STRING),
Field(name='genres', type=FSTYPE.STRING),
Field(name='imdb_id', type=FSTYPE.STRING),
Field(name='languages', type=FSTYPE.STRING),
Field(name='mins', type=FSTYPE.STRING),
Field(name='official_site', type=FSTYPE.STRING),
Field(name='regions', type=FSTYPE.STRING),
Field(name='release_data', type=FSTYPE.STRING),
Field(name='slug', type=FSTYPE.STRING),
Field(name='story', type=FSTYPE.STRING),
Field(name='tags', type=FSTYPE.STRING),
Field(name='year', type=FSTYPE.STRING),
Field(name='actor_ids', type=FSTYPE.STRING),
Field(name='director_ids', type=FSTYPE.STRING),
Field(name='dt', type=FSTYPE.STRING)
)
print(movie_schema)
接下来是新建 batch feature view.
feature_view_movie_name = "feature_view_movie"
batch_feature_view = project.get_feature_view(feature_view_movie_name)
if batch_feature_view is None:
batch_feature_view = project.create_batch_feature_view(name=feature_view_movie_name, owner='yancheng', schema=movie_schema, online = True, entity= cur_entity_name_movie, primary_key='movie_id', partitions=['dt'], ttl=-1)
获取 feature view, 查看基本信息:
batch_feature_view = project.get_feature_view(feature_view_movie_name)
batch_feature_view.print_summary()
将数据写入 max compute 表:
cur_task = batch_feature_view.write_table(ds, partitions={'dt':'20220830'})
cur_task.wait()
查看当前运行的 task 的信息:
print(cur_task.task_summary)
数据同步到 online store 中,供在线读取:
cur_task = batch_feature_view.publish_table({'dt':'20220830'})
cur_task.wait()
查看同步数据的 task 信息:
print(cur_task.task_summary)
我们按此步骤,依次导入 user 表,rating 表。
导入 user 表:
users_path = 'https://feature-store-test.oss-cn-beijing.aliyuncs.com/dataset/moviedata_all/users.csv'
ds = UrlDataSource(users_path, delimiter, omit_header)
print(ds)
user_schema = Schema(
Field(name='user_md5', type=FSTYPE.STRING),
Field(name='user_nickname', type=FSTYPE.STRING),
Field(name='ds', type=FSTYPE.STRING)
)
print(user_schema)
feature_view_user_name = "feature_view_users"
batch_feature_view = project.get_feature_view(feature_view_user_name)
if batch_feature_view is None:
batch_feature_view = project.create_batch_feature_view(name=feature_view_user_name, owner='yancheng', schema=user_schema, online = True, entity= cur_entity_name_user, primary_key='user_md5',ttl=-1, partitions=['ds'])
write_table_task = batch_feature_view.write_table(ds, {'ds':'20220830'})
write_table_task.wait()
print(write_table_task.task_summary)
cur_task = batch_feature_view.publish_table({'ds':'20220830'})
cur_task.wait()
print(cur_task.task_summary)
batch_feature_view = project.get_feature_view(feature_view_user_name)
batch_feature_view.print_summary()
导入 rating 表
ratings_path = 'https://feature-store-test.oss-cn-beijing.aliyuncs.com/dataset/moviedata_all/ratings.csv'
ds = UrlDataSource(ratings_path, delimiter, omit_header)
print(ds)
ratings_schema = Schema(
Field(name='rating_id', type=FSTYPE.STRING),
Field(name='user_md5', type=FSTYPE.STRING),
Field(name='movie_id', type=FSTYPE.STRING),
Field(name='rating', type=FSTYPE.STRING),
Field(name='rating_time', type=FSTYPE.STRING),
Field(name='dt', type=FSTYPE.STRING)
)
feature_view_rating_name = "feature_view_ratings"
batch_feature_view = project.get_feature_view(feature_view_rating_name)
if batch_feature_view is None:
batch_feature_view = project.create_batch_feature_view(name=feature_view_rating_name, owner='yancheng', schema=ratings_schema, online = True, entity= cur_entity_name_ratings, primary_key='rating_id', event_time='rating_time', partitions=['dt'])
batch_feature_view = project.get_feature_view(feature_view_rating_name)
batch_feature_view.print_summary()
至此,movie 表,item 表,rating 表都已导入完成。
7. 在线特征的获取¶
在导入 movie 表,item 表,rating 表的过程中,运行的 write_table 的操作,就是将 offline store (mc , spark) 中的数据,发布到 online store (hologres, igraph, redis) 。我们可以通过接口获取 online store 中的特征,便于分析数据。
feature_view_movie_name = "feature_view_movie"
batch_feature_view = project.get_feature_view(feature_view_movie_name)
ret_features_1 = batch_feature_view.get_online_features(join_ids={'movie_id':['26357307']}, features=['name', 'actores', 'regions'])
print("ret_features = ", ret_features_1)
feature_view_movie_name = "feature_view_movie"
batch_feature_view = project.get_feature_view(feature_view_movie_name)
ret_features_2 = batch_feature_view.get_online_features(join_ids={'movie_id':['30444960']}, features=['name', 'actores', 'regions'])
print("ret_features = ", ret_features_2)
8. 目标表 (Label Table)¶
注册为目标表,我们将导入的 feature_view_ratings 注册为 label 表。
owner = "yancheng"
label_table_name = 'fs_movie_1_feature_view_ratings_offline'
ds = MaxComputeDataSource(data_source_id=offline_datasource_id, table=label_table_name)
label_table = project.get_label_table(label_table_name)
if label_table is None:
label_table = project.create_label_table(owner, datasource=ds, event_time='rating_time')
9. 模型 (model)¶
从 OfflineStore 的角度讲,我们最终是训练出模型,变成服务进行业务的预测。 那么训练的样本可以从上面的 train_set 获得, 然后就是模型训练,最终会部署成服务。
9.1 train set¶
当我们要训练模型的时候,首先要构造样本表。样本表是由 label 数据和 特征数据组成。在与 FS 交互时, label 数据需要由客户提供,需要定义要获取的特征名称,然后根据主键进行 point-in-time join( 存在 event_time的情况下)
label_table_name = 'fs_movie_1_feature_view_ratings_offline'
output_ds = MaxComputeDataSource(data_source_id=offline_datasource_id)
train_set_output = TrainingSetOutput(output_ds)
feature_view_movie_name = "feature_view_movie"
feature_movie_selector = FeatureSelector(feature_view_movie_name, ['name', 'actores', 'regions','tags'])
feature_view_user_name = 'feature_view_users'
feature_user_selector = FeatureSelector(feature_view_user_name, ['user_nickname'])
train_set = project.create_training_set(label_table_name=label_table_name, train_set_output= train_set_output, feature_selectors=[feature_movie_selector, feature_user_selector])
print("train_set = ", train_set)
9.2 model¶
创建 model, model 名为: fs_model_rank_v1
model_name = "fs_model_rank_v1"
owner = 'yancheng'
deploy_config = EASDeployConfig(ak_id= '',region='',config='')
cur_model = project.get_model(model_name)
if cur_model is None:
cur_model = project.create_model(model_name, owner, train_set, deploy_config)
print("cur_model_train_set_table_name = ", cur_model.train_set_table_name)
9.3 导出样本表¶
实际训练的时候,我们需要导出样本表 指定 label 表以及各个 FeatureView 的分区, event_time
label_partitions = PartitionConfig(name = 'dt', value = '20220831')
label_input_config = LabelInputConfig(partition_config=label_partitions, event_time='1999-01-00 00:00:00')
movie_partitions = PartitionConfig(name = 'dt', value = '20220830')
feature_view_movie_config = FeatureViewConfig(name = 'feature_view_movie', partition_config=movie_partitions)
user_partitions = PartitionConfig(name = 'ds', value = '20220830')
feature_view_user_config = FeatureViewConfig(name = 'feature_view_users', partition_config=user_partitions)
feature_view_config_list = [feature_view_movie_config, feature_view_user_config]
train_set_partitions = PartitionConfig(name = 'dt', value = '20220831')
train_set_output_config = TrainSetOutputConfig(partition_config=train_set_partitions)
根据指定条件,导出样本表
task = cur_model.export_train_set(label_input_config, feature_view_config_list, train_set_output_config)
task.wait()
查看 task 运行状态
print(task.summary)